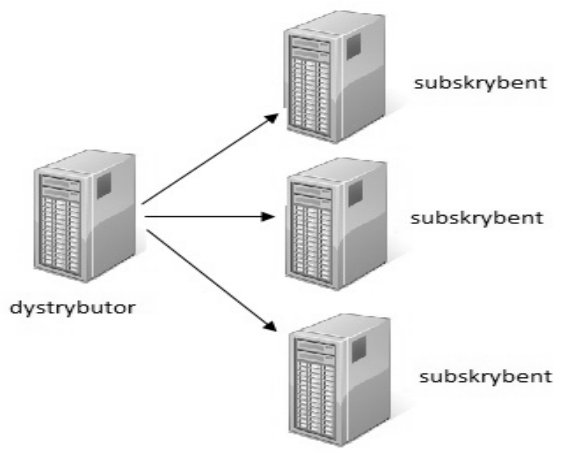
Pytanie 1
W języku SQL, dla dowolnych zbiorów danych w tabeli Uczniowie, aby uzyskać rekordy zawierające tylko uczennice o imieniu "Aleksandra", które urodziły się po roku "1998", należy sformułować zapytanie
A. SELECT * FROM Uczniowie WHERE imie="Aleksandra" AND rok_urodzenia > "1998"
B. SELECT * FROM Uczniowie WHERE imie ="Aleksandra" OR rok_urodzenia < "1998"
C. SELECT * FROM Uczniowie WHERE imie="Aleksandra" OR rok_urodzenia > "1998"
D. SELECT * FROM Uczniowie WHERE imie="Aleksandra" AND rok_urodzenia < "1998"
Pozostałe odpowiedzi niestety mają błędy w logice, co prowadzi do złych wyników. Jak używasz operatora OR, to istnieje szansa, że wyniki obejmą rekordy, które spełniają tylko jeden warunek, co nie pasuje do tego, co chciałeś uzyskać. Na przykład, zapytanie 'SELECT * FROM Uczniowie WHERE imie="Aleksandra" OR rok_urodzenia < "1998";' pokaże wszystkie Aleksandry, jak też wszystkie osoby urodzone przed 1998 rokiem, co jest kompletnie nie na miejscu, bo szukasz tylko tych urodzonych po 1998. Podobnie z użyciem operatora AND z warunkiem 'rok_urodzenia < "1998"', to także jest błędne, bo nie spełnia wymagań dotyczących urodzin po 1998 roku. Ważne jest, by operatorzy logiczni byli używani przemyślanie, żeby uniknąć niechcianych wyników. Często ludzie mylą AND z OR, co prowadzi do wniosków, które są dalekie od prawdy. W SQL musisz być precyzyjny w definiowaniu warunków, żeby wyniki pasowały do tego, co chcesz uzyskać.