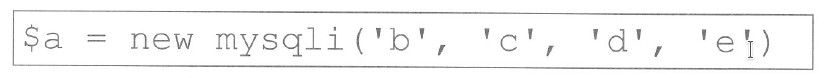Pytanie 1
Przykład zapytania SQL przedstawia instrukcję:
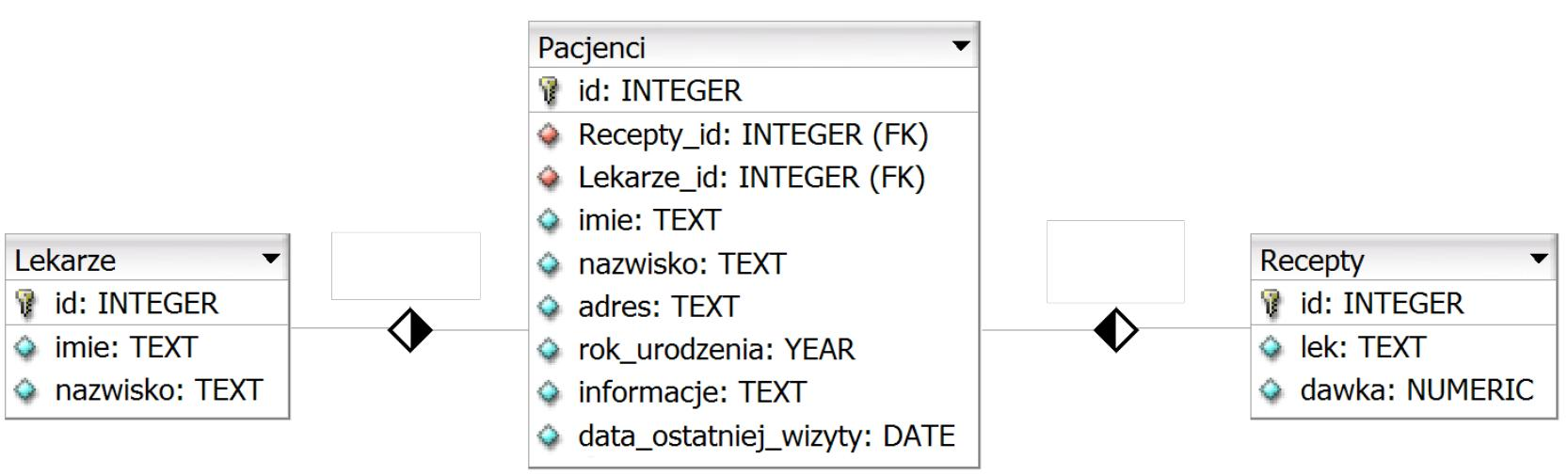
UPDATE katalog SET katalog.cena = [cena]*1.1;
A. krzyżowej
B. usuwającej
C. dołączającej
D. aktualizującej
Instrukcja SQL przedstawiona w pytaniu używa słowa kluczowego UPDATE co jest charakterystyczne dla kwerend aktualizujących. Komenda ta modyfikuje istniejące dane w tabeli poprawiając je zgodnie z podanymi kryteriami. W tym przykładzie wszystkie wartości w kolumnie cena tabeli katalog są zwiększane o 10 procent co jest typowym zastosowaniem instrukcji aktualizującej. W praktyce takie zmiany są niezbędne w przypadku modyfikacji cen produktów lub aktualizacji informacji biznesowych. Stosowanie kwerend aktualizujących wymaga zachowania szczególnej ostrożności aby nie naruszyć integralności danych. Dobre praktyki obejmują przygotowanie backupu danych przed wykonaniem operacji oraz przetestowanie kwerendy na mniejszym zbiorze danych w celu uniknięcia błędów. Aktualizacja danych to jedna z najczęstszych operacji w systemach bazodanowych dlatego zrozumienie mechanizmu działania kwerend SQL tego typu jest kluczowe dla efektywnego zarządzania danymi w każdej organizacji. SQL jako język deklaratywny umożliwia łatwe definiowanie co chcemy osiągnąć bez konieczności szczegółowego opisywania jak to zrobić co ułatwia pracę z dużymi i złożonymi zbiorami danych.