Pytanie 1
Który z poniższych znaczników HTML jest używany do tworzenia struktury strony internetowej?
A. <aside>
B. <input>
C. <em>
D. <mark>
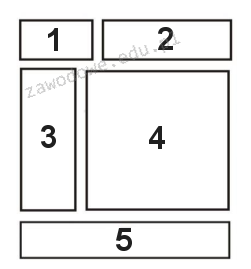
Znacznik <aside> jest poprawnym rozwiązaniem, ponieważ jest używany do definiowania treści, która jest powiązana z otaczającym kontekstem, ale nie jest kluczowa dla głównego przebiegu informacji. Z perspektywy budowy struktury strony internetowej, <aside> doskonale wpisuje się w koncepcję bocznych paneli, przypisów, lub dodatkowych informacji, które wzbogacają główną treść. Przykładem zastosowania może być umieszczenie sekcji z cytatami, powiązanymi artykułami lub innymi treściami uzupełniającymi. Zgodnie z zasadami semantyki HTML5, <aside> pozwala na lepszą interpretację treści przez przeglądarki oraz narzędzia do analizy SEO, co przyczynia się do poprawy dostępności i użyteczności strony. W praktyce, korzystanie z semantycznych znaczników, takich jak <aside>, wspiera także tworzenie bardziej czytelnych i strukturalnych dokumentów, co jest zgodne z najlepszymi praktykami w tworzeniu stron internetowych.