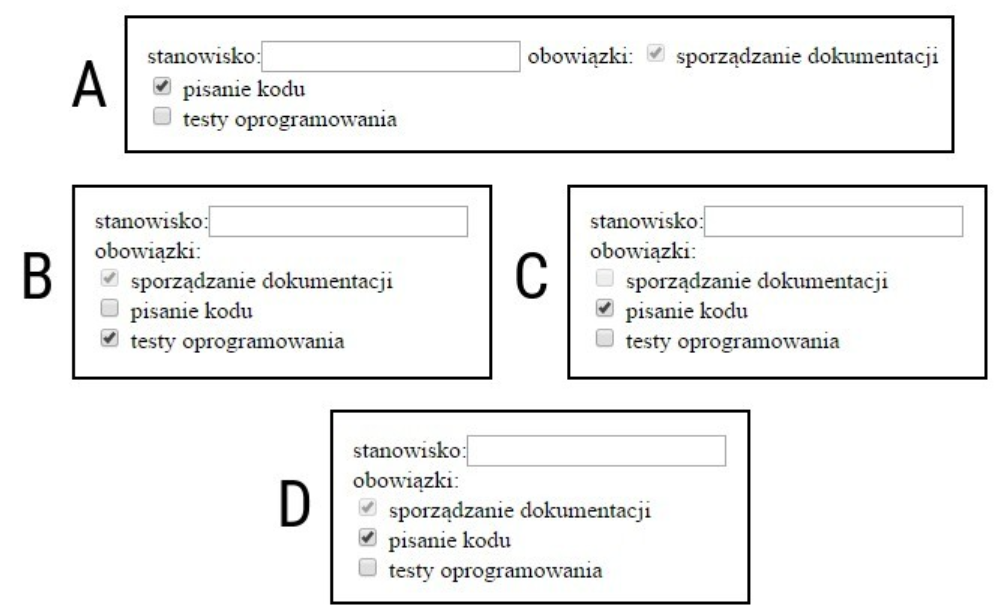
Pytanie 1
Jakie dane zostaną wyświetlone po wykonaniu poniższych poleceń? bool gotowe=true; cout<<gotowe;
A. tak
B. nie
C. 0
D. 1
W wyniku wykonania przedstawionych instrukcji, zostanie wypisane "1". Wynika to z faktu, że zmienna typu bool w języku C++ jest reprezentowana jako liczba całkowita, gdzie wartość "true" jest interpretowana jako "1", a "false" jako "0". Kiedy wykonujemy instrukcję z użyciem cout, która jest standardowym strumieniem wyjściowym w C++, zmienna gotowe, która przechowuje wartość true, zostanie przekonwertowana na jej reprezentację liczbową, co skutkuje wypisaniem "1" na ekran. W praktyce, zrozumienie konwersji typów danych w C++ jest kluczowe dla programowania, zwłaszcza w kontekście obliczeń logicznych i kontroli przepływu programu. Standardy C++ określają zasady konwersji typów, co wpływa na optymalizację kodu oraz unikanie błędów w logice programowania, dlatego wiedza na ten temat jest niezbędna dla każdego programisty.