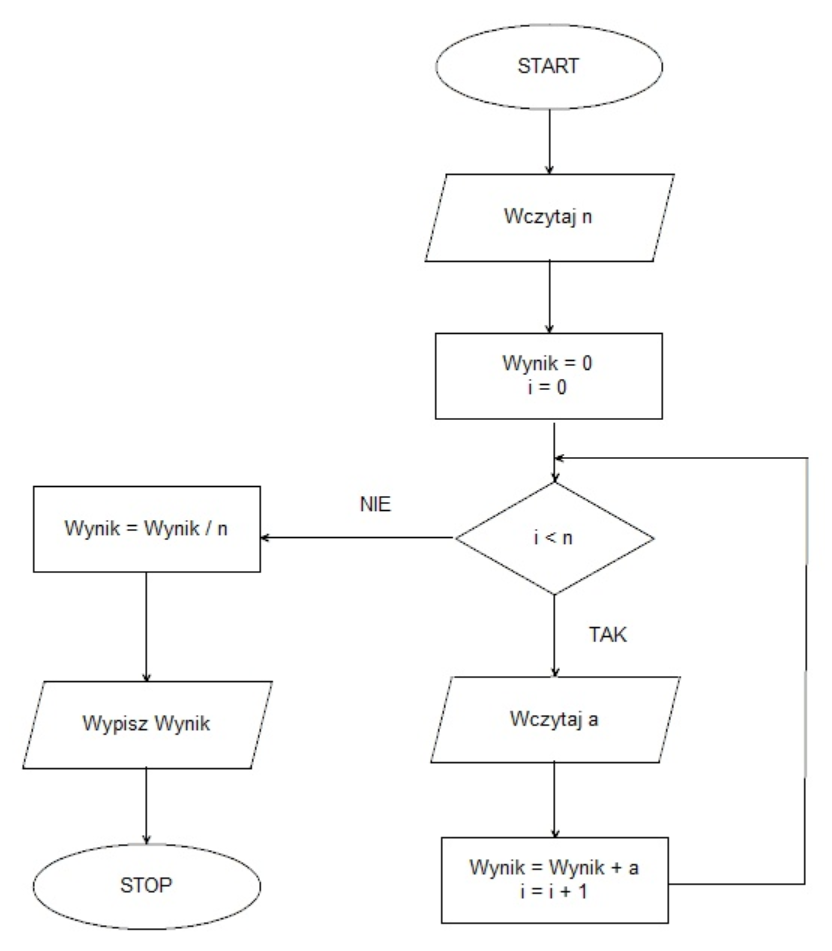
Pytanie 1
Czym jest proces normalizacji tabel w kontekście baz danych?
A. wprowadzenie nowych rekordów do bazy
B. wyłącznie stworzenie tabel oraz relacji w bazie
C. wizualizacja struktury bazy danych
D. analiza i optymalizacja bazy danych
Normalizacja tabel to kluczowy proces w projektowaniu baz danych, który ma na celu minimalizację redundancji danych oraz zapewnienie ich integralności. Proces ten polega na organizowaniu danych w taki sposób, aby zmniejszyć powtarzalność oraz eliminować potencjalne anomalia podczas operacji na bazie, takich jak wstawianie, aktualizowanie czy usuwanie danych. Standardowe formy normalne, takie jak pierwsza, druga czy trzecia forma normalna, definiują zasady, według których można osiągnąć ten cel. Na przykład, w trzeciej formie normalnej, żadne niekluczowe atrybuty nie mogą być zależne od innych atrybutów, co pozwala na lepsze zarządzanie danymi. W praktyce, normalizacja może przyczynić się do efektywności zapytań SQL oraz ułatwiać zarządzanie danymi poprzez tworzenie relacji między tabelami. Przykładem może być rozdzielenie danych klienta i zamówienia do osobnych tabel, co pozwala na łatwiejsze aktualizacje informacji o kliencie bez konieczności modyfikowania całej historii zamówień. W ten sposób normalizacja wspiera standardy branżowe, takie jak ANSI SQL, a także najlepsze praktyki w zakresie projektowania baz danych.