Pytanie 1
W kodzie HTML znajdziemy formularz. Jaki rezultat zostanie pokazany przez przeglądarkę, jeśli użytkownik wprowadził do pierwszego pola wartość "Przykładowy text"?
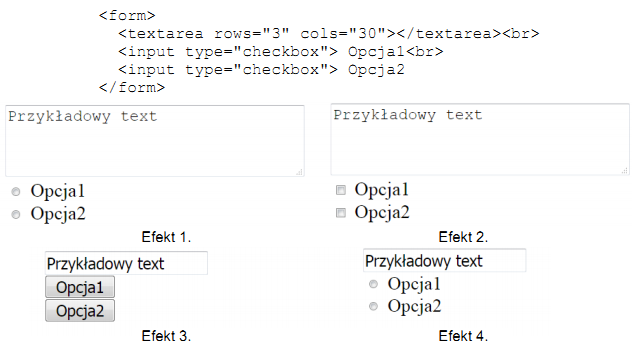
A. Efekt 4
B. Efekt 3
C. Efekt 1
D. Efekt 2
Efekt 2 jest prawidłowy, ponieważ odpowiada dokładnemu odwzorowaniu HTML. Kod zawiera element <textarea> oraz dwa pola typu checkbox. Przeglądarka wyświetla pole tekstowe o określonym rozmiarze, gdzie użytkownik może wpisać tekst. Checkboxy pozwalają na wybór opcji, niezależnych od siebie, co odróżnia je od radiobuttonów. Przykładowy text wpisany w pole <textarea> zostanie wyświetlony w miejscu tego pola, co jest dobrze widoczne na obrazie odpowiadającym efektowi 2. Warto pamiętać, że <textarea> stosuje się do dłuższych form tekstu, co jest standardem w projektowaniu formularzy. Użycie checkboxów jest zgodne z dobrymi praktykami, gdy użytkownik może zaznaczyć dowolną liczbę opcji. Jest to ważne, aby dostarczyć użytkownikowi intuicyjny interfejs do wprowadzania i wyboru danych. W HTML ważne jest, aby kod był semantyczny i zgodny z oczekiwaniami użytkowników, co ten przykład dobrze ilustruje. Formularze powinny być zawsze testowane pod kątem użyteczności i poprawności w różnych przeglądarkach.