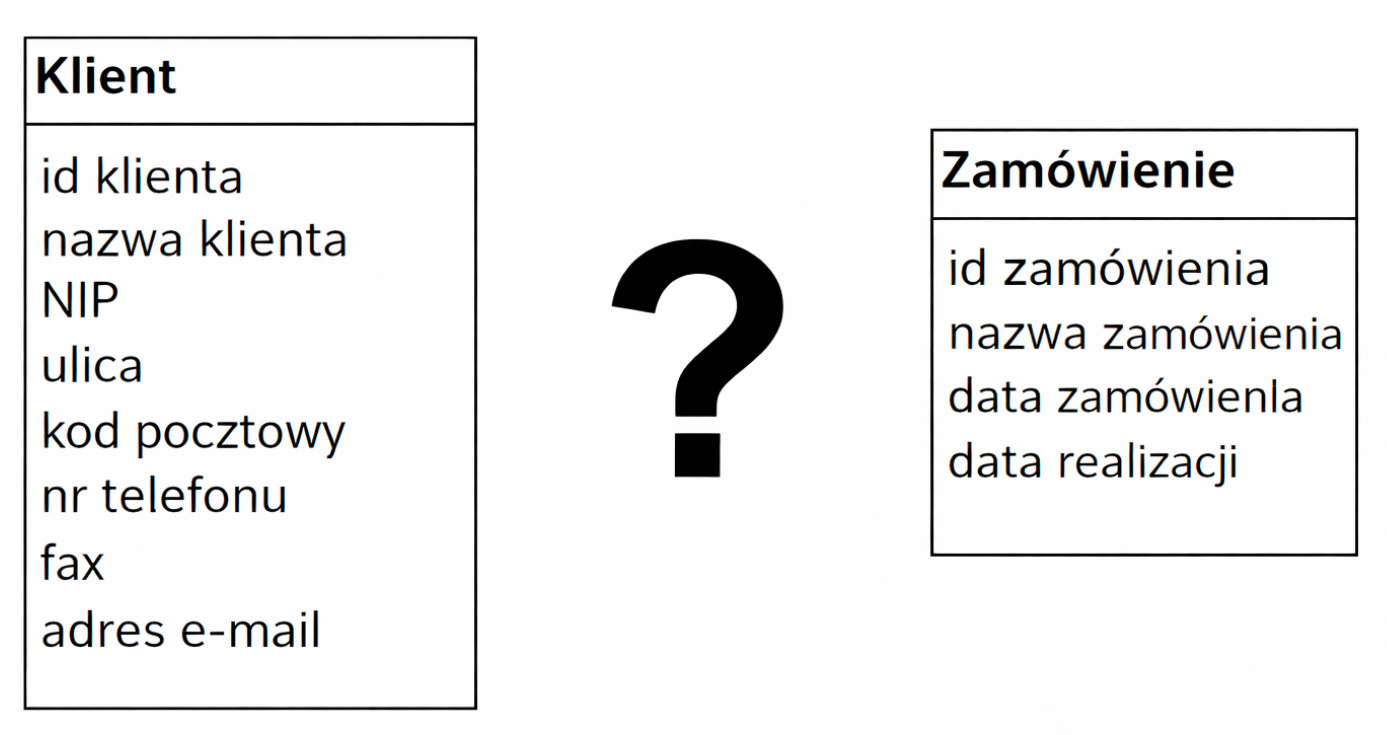
Pytanie 1
Instrukcję for można zastąpić inną instrukcją
A. switch
B. while
C. case
D. continue
Instrukcja `while` jest poprawnym zamiennikiem dla instrukcji `for` w kontekście iteracji, ponieważ obie służą do powtarzania bloków kodu, dopóki spełniony jest określony warunek. Główna różnica polega na sposobie deklaracji warunków iteracji. W instrukcji `for` często używamy jej do iteracji po znanym zakresie, np. od 0 do n, co jest typowe w wielu zastosowaniach, takich jak przetwarzanie elementów tablicy. Natomiast `while` idealnie nadaje się do sytuacji, gdzie liczba iteracji jest nieznana na początku i zależy od dynamicznie ocenianych warunków. Przykładem może być przetwarzanie danych, gdzie pętla `while` kontynuuje działanie, aż do momentu, gdy nie napotka na wartość końcową, co jest szczególnie przydatne w algorytmach przetwarzania strumieni danych. Ponadto, od strony wydajnościowej, wybór między `for` a `while` powinien być uzależniony od contextu, w jakim są używane. Dobrą praktyką jest dopasowanie rodzaju pętli do specyfiki problemu, co zwiększa czytelność i efektywność kodu.