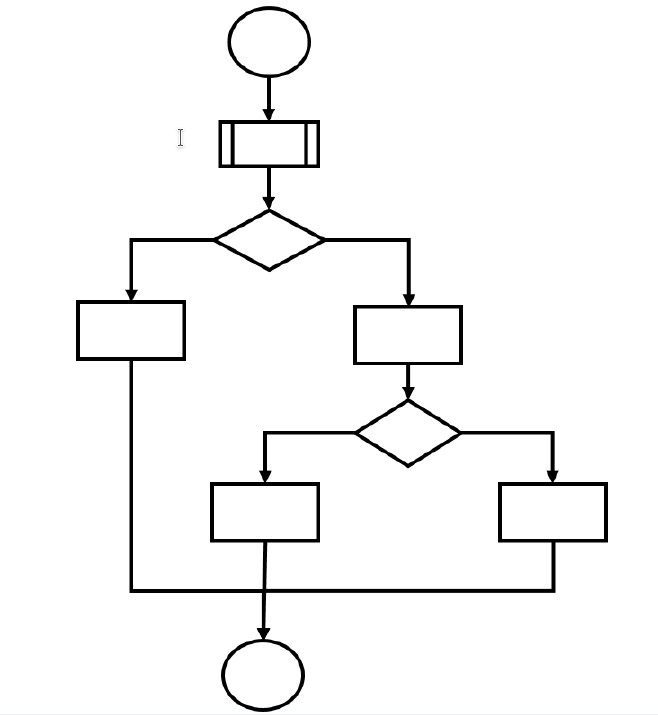
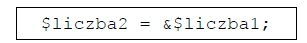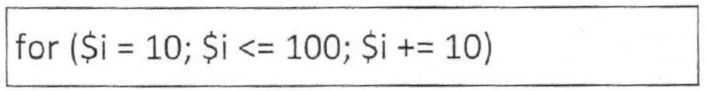Pytanie 1
Który efekt został zaprezentowany na filmie?
A. Zmniejszenie kontrastu zdjęcia.
B. Zwiększenie ostrości zdjęcia.
C. Zmiana jasności zdjęć.
D. Przenikanie zdjęć.
Poprawnie wskazany efekt to przenikanie zdjęć, często nazywane też płynnym przejściem (ang. crossfade). Polega to na tym, że jedno zdjęcie stopniowo zanika, jednocześnie drugie pojawia się z narastającą widocznością. W praktyce technicznej realizuje się to najczęściej przez zmianę przezroczystości (opacity) dwóch warstw – jedna warstwa z pierwszym obrazem ma zmniejszaną wartość opacity z 1 do 0, a druga z kolejnym zdjęciem zwiększaną z 0 do 1. Na stronach WWW taki efekt robi się zwykle za pomocą CSS (transition, animation, keyframes) albo JavaScriptu, czasem z użyciem bibliotek typu jQuery czy gotowych sliderów. Moim zdaniem to jest jeden z podstawowych efektów, który warto umieć odtworzyć, bo pojawia się w galeriach, sliderach na stronach głównych, prezentacjach produktów czy prostych pokazach slajdów. W materiałach multimedialnych, np. w edycji wideo, dokładnie ten sam efekt nazywa się przejściem typu „cross dissolve” lub „fade”, i zasada działania jest identyczna – płynne nakładanie się dwóch klatek obrazu w czasie. Dobre praktyki mówią, żeby nie przesadzać z czasem trwania przenikania: zwykle 0,5–1,5 sekundy daje przyjemny, profesjonalny wygląd, bez wrażenia „zamulenia” interfejsu. Warto też pilnować spójności – jeśli na stronie używasz przenikania w jednym miejscu, dobrze jest utrzymać podobny styl animacji w innych elementach, żeby całość wyglądała konsekwentnie i nie rozpraszała użytkownika. W kontekście multimediów na WWW przenikanie jest też korzystne wydajnościowo, bo operuje głównie na właściwości opacity i transformacjach, które przeglądarki potrafią optymalizować sprzętowo.