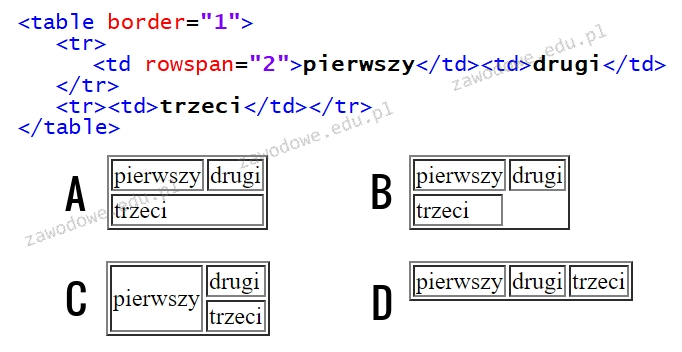
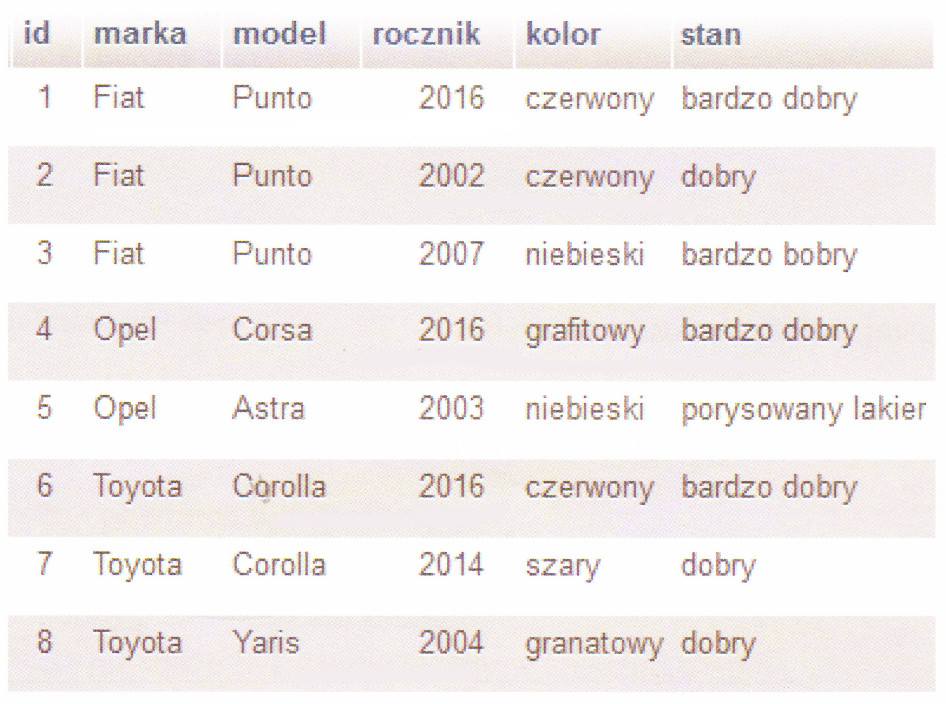
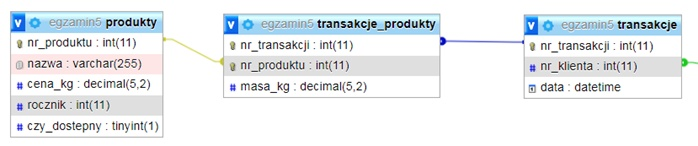
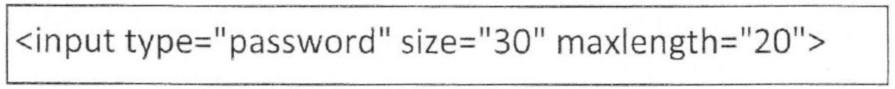Pytanie 1
W sklepie internetowym wykorzystuje się tabelę faktura. W trakcie generowania faktury pole dataPlatnosci nie zawsze jest uzupełnione. Aby to skorygować, pod koniec dnia należy wprowadzić bieżącą datę do wierszy, gdzie to pole jest puste. W tym celu można wykorzystać kwerendę
A. UPDATE faktury SET dataPlatnosci=CURDATE() WHERE dataplatnosci = '0000-00-00'
B. UPDATE faktury SET dataPlatnosci=CURTIME() WHERE dataPlatnosci IS NOT NULL
C. UPDATE faktury SET dataPlatnosci=CURDATE() WHERE dataPlatnosci IS NULL
D. UPDATE faktury SET dataPlatnosci=CURTIME() WHERE id = 3
Poprawna odpowiedź to 'UPDATE faktury SET dataPlatnosci=CURDATE() WHERE dataPlatnosci IS NULL;'. Ta kwerenda jest odpowiednia, ponieważ aktualizuje pole 'dataPlatnosci' w tabeli 'faktury' tylko w tych wierszach, gdzie to pole jest puste (NULL). Użycie funkcji CURDATE() pozwala na wprowadzenie aktualnej daty, co jest praktycznym rozwiązaniem dla problemu niewypełnionych dat płatności. Warto pamiętać, że korzystanie z NULL jest standardem w bazach danych, który oznacza brak wartości. Z perspektywy dobrych praktyk w zarządzaniu danymi, ważne jest, aby dbać o pełność danych, co wpływa na późniejsze analizy i generowanie raportów. Tego rodzaju kwerendy powinny być stosowane regularnie, aby zapewnić integralność i aktualność danych w systemie, co jest kluczowe w kontekście e-commerce, gdzie terminowość transakcji ma istotne znaczenie. Na przykład, w sytuacji, gdy system generuje raporty dotyczące płatności, brak daty płatności może prowadzić do nieprawidłowych wniosków.