Pytanie 1
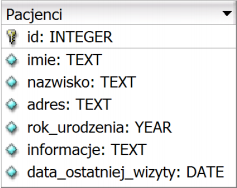
$x = mysql_query('SELECT * FROM mieszkanci'); if (!$x) echo "??????????????????????????????"; W podanym kodzie PHP, w miejscu znaków zapytania powinien wyświetlić się komunikat:
A. Zapytania zakończono sukcesem
B. Błąd w trakcie przetwarzania zapytania
C. Nieprawidłowa nazwa bazy danych
D. Złe hasło do bazy danych
W przedstawionym kodzie PHP mamy do czynienia z próbą wykonania zapytania SQL do bazy danych przy pomocy funkcji mysql_query. Ta funkcja zwraca wartość false, jeśli wystąpił błąd w trakcie przetwarzania zapytania. W kontekście tego kodu, komunikat 'Błąd przetwarzania zapytania.' jest odpowiedni, ponieważ wskazuje, że zapytanie nie zostało poprawnie wykonane. Istotne jest, aby programista zrozumiał, że błędy mogą wynikać z różnych przyczyn, takich jak błędna składnia SQL, problemy z połączeniem do bazy danych lub inne czynniki techniczne. Ważną praktyką jest dodawanie mechanizmów obsługi błędów, które mogą dać więcej informacji na temat problemu, np. użycie mysql_error() do uzyskania szczegółowych informacji o błędzie. Standardy dotyczące programowania w PHP oraz najlepsze praktyki wskazują na konieczność stosowania try-catch dla lepszej kontroli błędów oraz logowania, co może pomóc w diagnozowaniu problemów na etapie produkcyjnym. Warto zaznaczyć, że mysql_query jest przestarzałą funkcją, a obecnie zaleca się użycie mysqli lub PDO do komunikacji z bazą danych, co poprawia bezpieczeństwo i wydajność aplikacji.