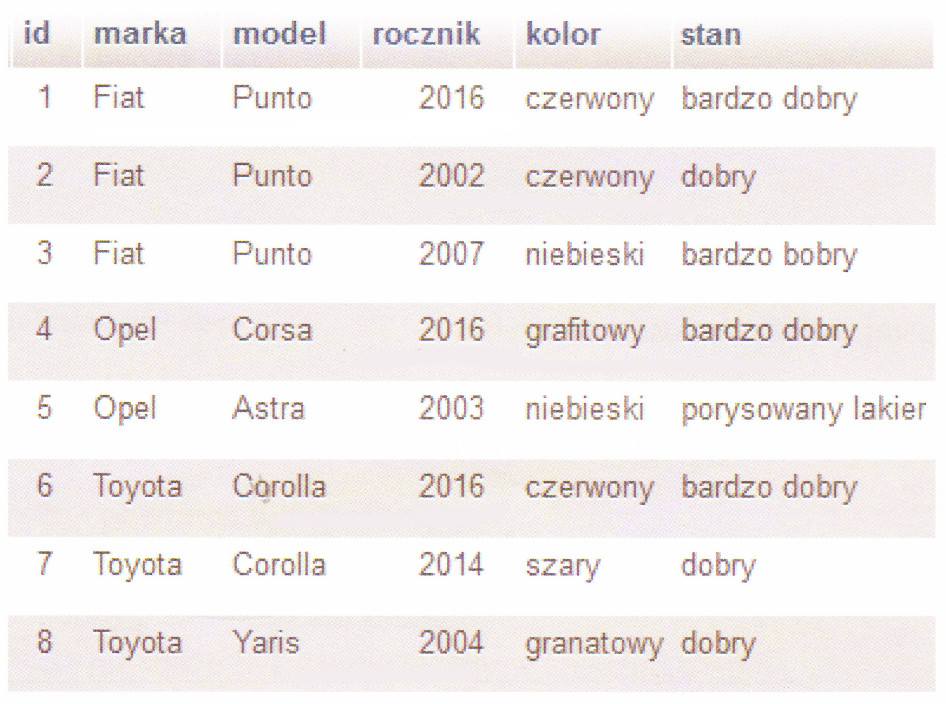
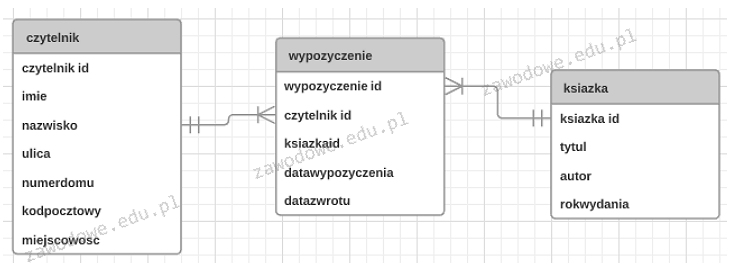
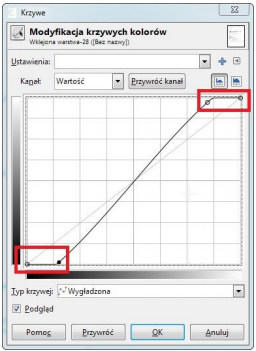
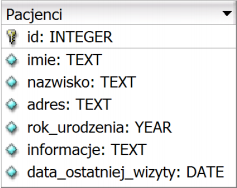
Pytanie 1
Celem testów wydajnościowych jest ocena
A. możliwości oprogramowania do funkcjonowania w warunkach niewłaściwej pracy systemu
B. możliwości oprogramowania do funkcjonowania w warunkach błędnej pracy sprzętu
C. poziomu spełnienia wymagań dotyczących wydajności przez system bądź moduł
D. sekwencji zdarzeń, w której prawdopodobieństwo wystąpienia każdego zdarzenia zależy wyłącznie od wyniku zdarzenia poprzedniego
Odpowiedzi sugerujące, że testy wydajnościowe mają na celu sprawdzenie ciągu zdarzeń, w którym prawdopodobieństwo każdego zdarzenia zależy jedynie od wyniku poprzedniego, dotyczą zupełnie innej dziedziny – statystyki i teorii prawdopodobieństwa. W kontekście testów wydajnościowych mówimy o analizie zachowania systemu w odpowiedzi na obciążenie, a nie o modelowaniu zdarzeń losowych. Kolejne koncepcje, takie jak zdolność oprogramowania do działania w warunkach wadliwej pracy systemu lub sprzętu, odnoszą się do testów odpornościowych i awaryjnych, a nie do testów wydajnościowych. Testy te mają na celu zbadanie, jak system reaguje na sytuacje awaryjne, jednak nie są one bezpośrednio związane z oceną jego wydajności. Te nieporozumienia mogą wynikać z mylnego założenia, że testy wydajnościowe obejmują wszystkie aspekty funkcjonalności systemu, podczas gdy w rzeczywistości koncentrują się one na specyficznych wymaganiach dotyczących szybkości i efektywności działania. Właściwe rozumienie testów wydajnościowych jako narzędzia do pomiaru i optymalizacji wydajności systemu jest kluczowe dla zapewnienia jego sukcesu na rynku. Każda z tych nieprawidłowych odpowiedzi prowadzi do niedosłownego zrozumienia celów i metodologii stosowanych w testach wydajnościowych, co może skutkować poważnymi błędami w procesie wytwarzania oprogramowania.