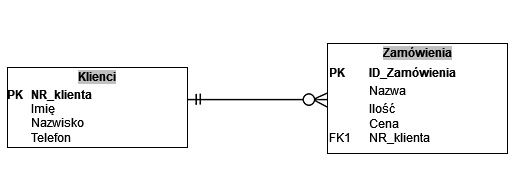
Pytanie 1
Normalizacja tabel to proces, którego celem jest
A. dodanie danych do bazy
B. sprawdzenie i optymalizację bazy danych
C. wizualizacja bazy
D. wyłącznie stworzenie tabel oraz relacji w bazie
Normalizacja tabel jest kluczowym procesem w projektowaniu baz danych, który ma na celu usprawnienie struktury danych poprzez eliminację redundancji i zapewnienie integralności danych. Proces ten składa się z kilku kroków, które prowadzą do stworzenia dobrze zorganizowanej bazy danych. Głównym celem normalizacji jest zminimalizowanie powielania danych, co w rezultacie prowadzi do optymalizacji przestrzeni dyskowej oraz zwiększenia wydajności zapytań. Przykładem zastosowania normalizacji jest podział tabeli zawierającej informacje o klientach i zamówieniach na dwie odrębne tabele. W ten sposób, każdy klient ma swoje unikalne dane w jednej tabeli, natomiast w drugiej tabeli zapisywane są tylko odniesienia do klientów zamiast ich powtórzeń. Dobre praktyki związane z normalizacją uwzględniają różne formy normalne, z których każda ma swoje zasady, np. pierwsza forma normalna (1NF) wymaga, aby każda kolumna w tabeli zawierała tylko atomowe wartości. Wysoka jakość projektowania baz danych, w tym normalizacja, znacząco wpływa na późniejsze zarządzanie danymi oraz ich analizy.