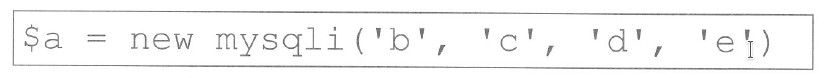Pytanie 1
Poziom izolacji transakcji Repeatable Read (tryb powtarzalnego odczytu) używany przez MS SQL jest związany z problemem
A. utraty aktualizacji
B. odczytów widm
C. niepowtarzalnych odczytów
D. brudnych odczytów
Wszystkie pozostałe odpowiedzi dotyczą problemów, które nie są bezpośrednio związane z poziomem izolacji Repeatable Read. Utrata aktualizacji występuje, gdy dwie transakcje odczytują ten sam wiersz i obie próbują go zaktualizować. Problem ten jest bardziej związany z poziomem izolacji Read Committed, gdzie jedno z odczytów może nadpisać zmiany dokonane przez drugie, co prowadzi do utraty ważnych informacji. Brudne odczyty z kolei występują, gdy transakcja odczytuje dane zmienione przez inną transakcję, która jeszcze nie została zatwierdzona. Ten problem jest charakterystyczny dla najniższego poziomu izolacji, czyli Read Uncommitted, gdzie brak jakiejkolwiek kontroli nad odczytem danych skutkuje niebezpieczeństwem uzyskania nieaktualnych lub niepoprawnych informacji. Niepowtarzalne odczyty natomiast to sytuacje, w których iż dane mogą zmieniać się pomiędzy dwoma odczytami w tej samej transakcji. Problem ten występuje w poziomie Read Committed, gdzie zmiany dokonane przez inne transakcje mogą być widoczne dla aktualnej transakcji, co prowadzi do niespójności w wynikach. Tak więc, choć wszystkie wymienione zjawiska są ważnymi problemami w zarządzaniu transakcjami, tylko odczyty widm są specyficznie związane z poziomem izolacji Repeatable Read.