Pytanie 1
Który z obrazków ilustruje efekt działania podanego fragmentu kodu HTML?
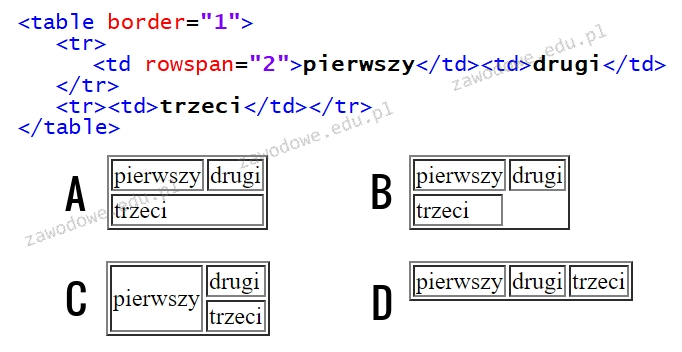
A. Obrazek D
B. Obrazek B
C. Obrazek A
D. Obrazek C
Odpowiedzi inne niż C są niepoprawne ponieważ nie uwzględniają poprawnie działania atrybutu rowspan co prowadzi do błędnego renderowania tabeli. W przypadku błędnego rozumienia atrybutu rowspan możemy obserwować sytuacje gdzie komórki tabeli są wyświetlane w niewłaściwych miejscach co może sugerować że atrybut ten jest błędnie zrozumiany jako wpływający na szerokość a nie na wysokość komórki. Często spotykanym błędem jest zakładanie że rowspan działa podobnie jak colspan co prowadzi do błędnego ułożenia komórek w tabeli. Ważne jest aby zrozumieć że rowspan definiuje ile wierszy ma zajmować dana komórka a nie ile kolumn co jest kluczowe dla prawidłowego zrozumienia układów tabelarycznych w HTML. Takie błędy mogą prowadzić do nieczytelnych i niepoprawnie zorganizowanych danych na stronie WWW co jest szczególnie problematyczne w przypadku stron które muszą być kompatybilne z różnymi urządzeniami i technologiami asystującymi. Poprawne stosowanie atrybutów rowspan i colspan jest fundamentalne dla tworzenia dostępnych i estetycznych układów tabelarycznych.