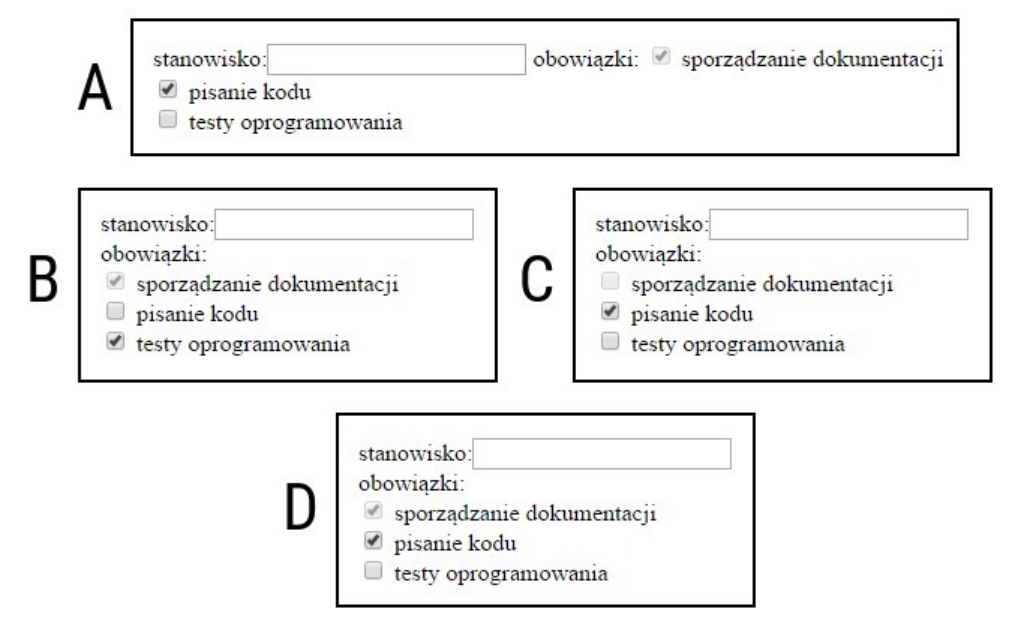
Pytanie 1
W dokumentacji języka PHP znajduje się informacja dotycząca jednej z jego funkcji:
„Warning. This extension was deprecated in PHP 5.5.0, and it was removed in PHP 7.0.0.”.
Zgodnie z tą informacją użycie tej funkcji jest:
A. przestarzałe od wersji PHP 5.5.0 i całkowicie usunięte w wersji 7.0.0.
B. niezalecane w wersji PHP 5.5.0 i dostępne od wersji 7.0.0.
C. dostępne w wersjach PHP od 5.5.0 do 7.0.0 (włącznie) i niedostępne w innych wersjach.
D. niemożliwe w wersjach PHP 5.5.0 lub starszych i dostępne dopiero od wersji 7.0.0.
Komunikat z dokumentacji PHP „Warning. This extension was deprecated in PHP 5.5.0, and it was removed in PHP 7.0.0.” oznacza dwa różne stany w cyklu życia funkcji/rozszerzenia. „Deprecated” od wersji 5.5.0 znaczy, że funkcja nadal działa, ale jej użycie jest oficjalnie niezalecane. Silnik PHP może generować ostrzeżenia (E_DEPRECATED), a autorzy języka jasno sugerują, żeby migrować kod na nowsze, wspierane rozwiązania. „Removed w PHP 7.0.0” oznacza, że od tej wersji funkcja po prostu nie istnieje – próba jej użycia skończy się błędem typu „undefined function” lub „undefined extension”. Z mojego doświadczenia wynika, że taki status to sygnał alarmowy dla programisty: w nowych projektach nie używamy funkcji oznaczonych jako deprecated, a w istniejących aplikacjach planujemy refaktoryzację, zanim wejdziemy na wyższą wersję PHP. Dobrym przykładem jest stare rozszerzenie mysql_* – od PHP 5.5 było oznaczone jako przestarzałe, a w PHP 7 zostało usunięte i trzeba było przejść na mysqli lub PDO. W praktyce, gdy widzisz w dokumentacji „deprecated od wersji X”, powinieneś: sprawdzić zalecaną alternatywę, włączyć raportowanie błędów i ostrzeżeń na środowisku developerskim, usunąć stopniowo wszystkie wywołania danej funkcji. Branżową dobrą praktyką jest też testowanie aplikacji na docelowej wersji PHP przed aktualizacją produkcji, żeby właśnie takie usunięte funkcje wyłapać automatycznie w logach lub podczas testów jednostkowych. Twoja odpowiedź dokładnie to odczytała: od 5.5 funkcja jest przestarzała (deprecated), a w 7.0 całkowicie znika z języka.