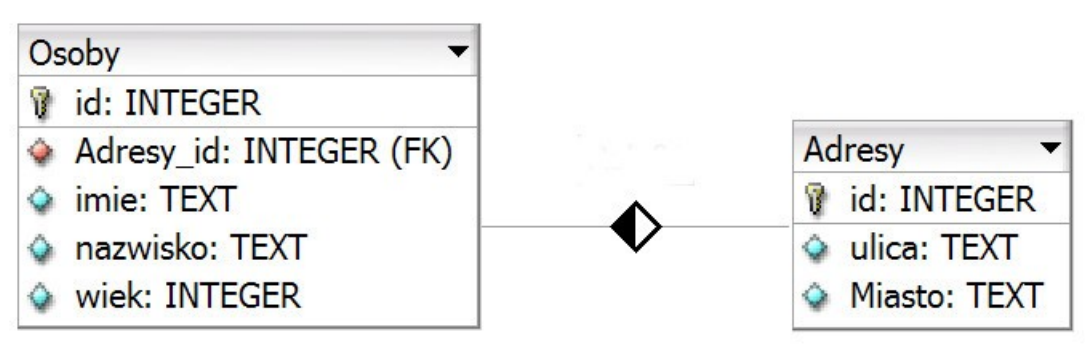
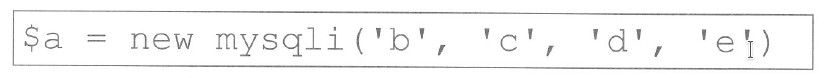Pytanie 1
W języku PHP nie można zrealizować
A. przetwarzania danych z formularzy
B. tworzenia dynamicznej treści strony
C. obróbki danych przechowywanych w bazach danych
D. zmiany dynamicznej zawartości strony HTML w przeglądarce
PHP, jako skryptowy język programowania po stronie serwera, nie jest w stanie dynamicznie zmieniać zawartości strony HTML w przeglądarce użytkownika po jej załadowaniu. Operacje, które wykonuje PHP, są realizowane na serwerze, a wyniki tych operacji przesyłane są jako statyczny HTML do przeglądarki. Oznacza to, że jakiekolwiek zmiany w treści strony muszą być przeprowadzane przed wysłaniem odpowiedzi do klienta. Dynamiczne zmiany w istniejącej zawartości HTML w przeglądarce są realizowane za pomocą JavaScriptu, który działa po stronie klienta. Na przykład, jeśli mamy formularz, który po wypełnieniu wymaga zmiany niektórej zawartości na stronie bez jej ponownego ładowania, to właśnie JavaScript, a nie PHP, będzie odpowiedzialny za te zmiany. PHP może generować zawartość w odpowiedzi na żądania, ale nie ma możliwości interakcji z już załadowanym DOM w przeglądarce. To ograniczenie wynika z architektury webowej, w której PHP i JavaScript pełnią różne role, co jest zgodne z ogólnymi standardami tworzenia aplikacji webowych, w tym modelu MVC (Model-View-Controller), gdzie PHP obsługuje model i widok, a JavaScript kontroler.