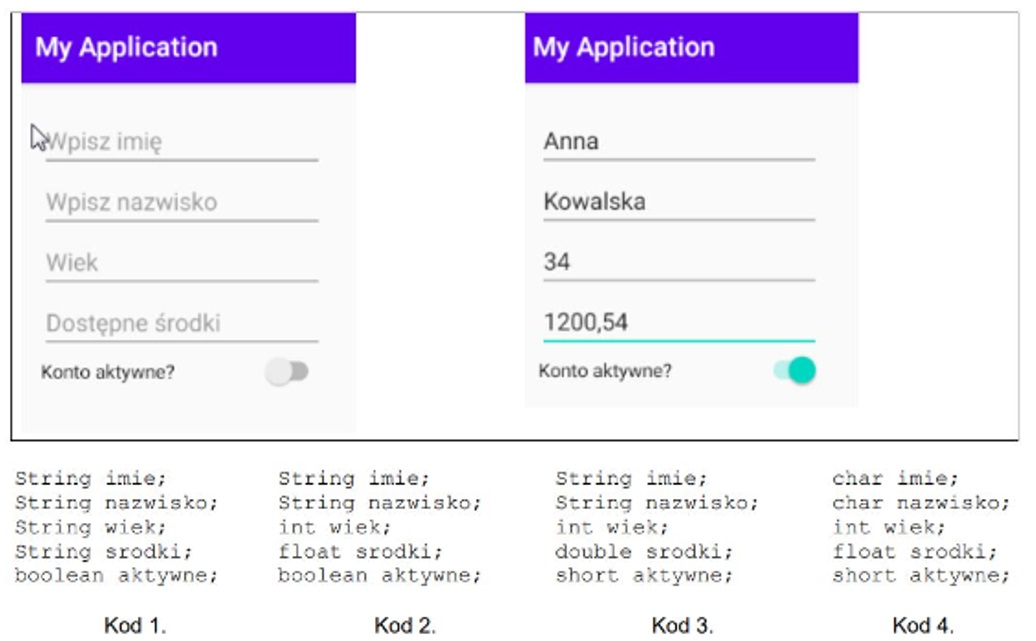
Pytanie 1
Jakie informacje można uzyskać na temat metod w klasie Point?
public class Point { public void Move(int x, int y) {...} public void Move(int x, int y, int z) {...} public void Move(Point newPt) {...} }
A. Są przeciążone.
B. Zawierają przeciążenie operatora.
C. Zawierają błąd, ponieważ nazwy metod powinny być różne.
D. Służą jako konstruktory w zależności od liczby argumentów.
Brak odpowiedzi na to pytanie.
Wyjaśnienie poprawnej odpowiedzi:
Metody klasy Point są przeciążone, co oznacza, że mogą mieć tę samą nazwę, ale różnią się liczbą lub typem parametrów. Przeciążenie metod to jedna z podstawowych technik programowania obiektowego, która pozwala na bardziej elastyczne projektowanie kodu. Dzięki temu programista może tworzyć metody dostosowane do różnych sytuacji, zachowując spójność nazw i intuicyjność użycia. To zwiększa czytelność i utrzymanie kodu, ponieważ wywołania metod o tej samej nazwie, ale różnych parametrach, są łatwe do zrozumienia i odnalezienia.
Metody klasy Point są przeciążone, co oznacza, że mogą mieć tę samą nazwę, ale różnią się liczbą lub typem parametrów. Przeciążenie metod to jedna z podstawowych technik programowania obiektowego, która pozwala na bardziej elastyczne projektowanie kodu. Dzięki temu programista może tworzyć metody dostosowane do różnych sytuacji, zachowując spójność nazw i intuicyjność użycia. To zwiększa czytelność i utrzymanie kodu, ponieważ wywołania metod o tej samej nazwie, ale różnych parametrach, są łatwe do zrozumienia i odnalezienia.