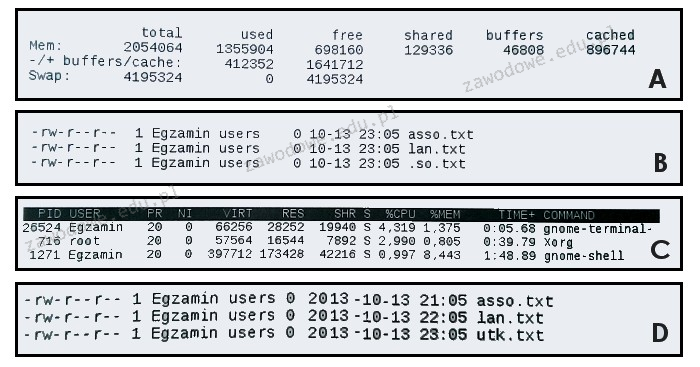
Pytanie 1
W systemie Linux polecenie touch jest używane do
A. znalezienia określonego wzorca w treści pliku
B. przeniesienia lub zmiany nazwy pliku
C. policzenia liczby linii, słów oraz znaków w pliku
D. stworzenia pliku lub zmiany daty edycji bądź daty ostatniego dostępu
Polecenie 'touch' w systemie Linux jest jednym z fundamentalnych narzędzi używanych do zarządzania plikami. Jego podstawową funkcją jest tworzenie nowych plików, a także aktualizowanie daty modyfikacji i daty ostatniego dostępu do istniejących plików. Kiedy wywołujemy 'touch', jeśli plik o podanej nazwie nie istnieje, zostaje on automatycznie utworzony jako pusty plik. To jest niezwykle przydatne w wielu scenariuszach, na przykład w skryptach automatyzacji, gdzie potrzebujemy szybko przygotować plik do dalszych operacji. Dodatkowo, zmiana daty modyfikacji pliku za pomocą 'touch' jest kluczowa w kontekście wersjonowania plików, gdyż pozwala na manipulowanie metadanymi plików w sposób, który może być zgodny z wymaganiami procesu. Dobrą praktyką jest również używanie opcji takich jak '-a' i '-m', które pozwalają odpowiednio na aktualizację daty ostatniego dostępu i daty modyfikacji bez zmiany pozostałych atrybutów. Warto zwrócić uwagę, że standardowe operacje na plikach, takie jak te wykonywane przez 'touch', są integralną częścią zarządzania systemem plików w Linuxie, co czyni zrozumienie ich działania kluczowym dla każdego administratora systemu.