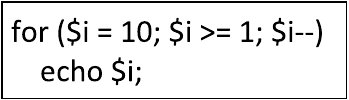Pytanie 1
Fragment kodu w PHP przedstawia się następująco (patrz ramka): Przy założeniu, że zmienna tablicowa $tab zawiera liczby naturalne, wynik działania programu polega na wypisaniu

A. elementu tablicy równemu wartości $tab[0]
B. tych elementów, które przewyższają wartość zmiennej $liczba
C. największego elementu w tablicy
D. najmniejszego elementu w tablicy
Zobaczmy teraz, co poszło nie tak z innymi odpowiedziami. W przypadku tej, co miała znaleźć najmniejszy element, to kod nie jest w stanie tego zrobić, ponieważ warunek if sprawdza, czy element jest większy, a powinien być mniejszy, żeby szukać minimum. Jakby zmienić na if ($element < $liczba), to byłoby ok. W innej odpowiedzi twierdzono, że program znajdzie element równy $tab[0], ale w kodzie nie ma żadnego porównania z tym pierwszym elementem, poza tym, że przypisujemy go do $liczba na początku. Brak tam dodatkowej logiki, żeby to ogarnąć. A w ostatniej odpowiedzi pisano o wypisywaniu elementów większych od $liczba, ale kod nie działa w ten sposób, bo nie ma tam nic, co by pozwalało na wypisywanie więcej niż jednego elementu. Program jedynie aktualizuje $liczba, żeby znaleźć największą wartość. Często takie pomyłki biorą się z braku zrozumienia, jak działa iteracja i porównania w programowaniu, gdzie trzeba dobrze rozumieć, jakie warunki i operacje są potrzebne.