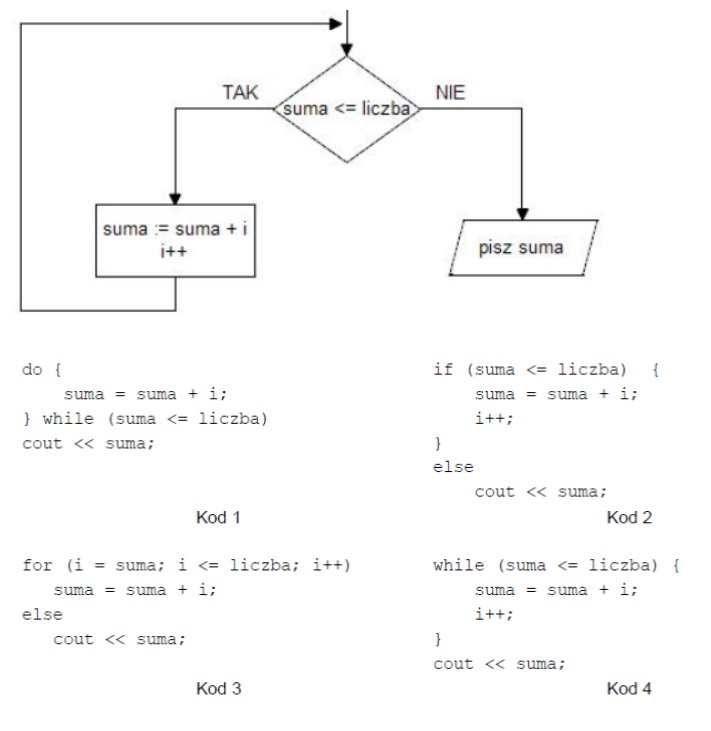
Pytanie 1
Jakie ma znaczenie "operacja wejścia" w kontekście programowania?
A. Wprowadzanie nowych funkcji do aplikacji
B. Naprawianie błędów w kodzie aplikacji
C. Przekazywanie danych do programu z zewnętrznych źródeł
D. Zmiana wartości zmiennych globalnych
Operacja wejścia w programowaniu polega na przekazywaniu danych do programu z zewnętrznego źródła, takiego jak klawiatura, plik lub strumień danych. W języku C++ typowym przykładem operacji wejścia jest `cin >> zmienna;`, która pobiera dane od użytkownika i przypisuje je do zmiennej. Operacje wejścia są niezbędne w interaktywnych aplikacjach, które wymagają danych od użytkownika w czasie rzeczywistym, umożliwiając dynamiczne przetwarzanie informacji.