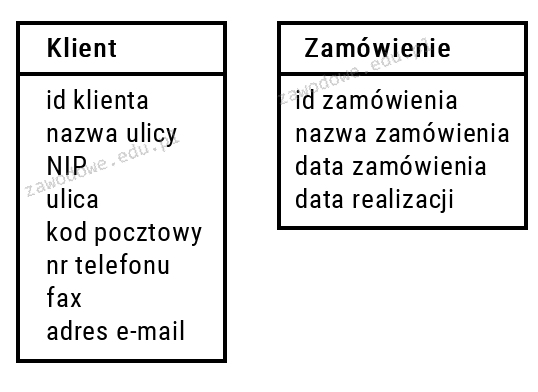
Pytanie 1
Została stworzona baza danych z tabelą podzespoły, która zawiera pola: model, producent, typ, cena. Aby uzyskać listę wszystkich modeli pamięci RAM od firmy Kingston uporządkowanych od najniższej do najwyższej ceny, należałoby użyć kwerendy:
A. SELECT model FROM podzespoły WHERE typ='RAM' OR producent='Kingston' ORDER BY cena DESC
B. SELECT model FROM podzespoły WHERE typ='RAM' AND producent='Kingston' ORDER BY cena DESC
C. SELECT model FROM podzespoły WHERE typ='RAM' AND producent='Kingston' ORDER BY cena ASC
D. SELECT model FROM producent WHERE typ='RAM' OR producent='Kingston' ORDER BY podzespoły ASC
Analizując niepoprawne odpowiedzi, można zauważyć kilka istotnych błędów koncepcyjnych, które prowadzą do błędnych wyników. W przypadku pierwszej z błędnych kwerend, użycie klauzuli ORDER BY cena DESC sprawia, że wyniki są sortowane od najdroższej do najtańszej, co jest sprzeczne z wymaganiem przedstawienia modeli w porządku rosnącym. Problem ten często wynika z błędnego zrozumienia celu sortowania, co może prowadzić do frustracji użytkowników poszukujących najkorzystniejszych cen. W innej z błędnych odpowiedzi, klauzula WHERE wykorzystuje operator OR zamiast AND, co skutkuje zwróceniem modeli RAM od różnych producentów, co jest niewłaściwe w kontekście zadania, które wymaga danych tylko od producenta Kingston. Ponadto, ostatnia odpowiedź zawiera również błąd w odniesieniu do źródła danych, wskazując na tabelę 'producent' zamiast 'podzespoły'. W SQL kluczowe jest zrozumienie struktury danych oraz logiczne formułowanie zapytań, aby uniknąć nieścisłości. Błędy te mogą wynikać z mylnego założenia, że każda zmiana w zapytaniu nie wpływa na jego integralność i wynik, co jest niebezpiecznym podejściem w praktyce programistycznej.