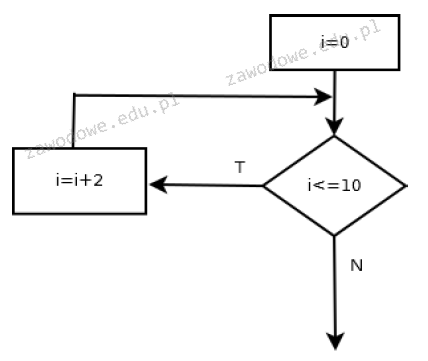
Pytanie 1
Jak można opisać przedstawiony obiekt w JavaScript?
| var obiekt1 = { x: 0, y: 0, wsp: function() { ... } } |
A. dwiema metodami i jedną właściwością
B. dwiema właściwościami i jedną metodą
C. trzema właściwościami
D. trzema metodami
Obiekt w języku JavaScript to struktura danych, która przechowuje zbiór właściwości, gdzie każda właściwość jest parą klucz-wartość. W podanym przykładzie mamy obiekt o nazwie 'obiekt1' zdefiniowany za pomocą literału obiektowego. Składa się on z dwóch właściwości 'x' i 'y', które mają przypisane wartości liczby całkowitej zero oraz jednej metody 'wsp', która jest funkcją. Właściwości 'x' i 'y' są prostymi wartościami liczbowymi, a metoda 'wsp' jest zdefiniowana jako funkcja, co oznacza, że można ją wywoływać, aby wykonywać pewne operacje. Tego typu struktury są często używane w JavaScript do tworzenia obiektów reprezentujących dane, jak współrzędne punktów na płaszczyźnie. Dzięki możliwości definiowania metod, obiekty mogą wykonywać operacje na swoich danych, co jest zgodne z zasadami programowania obiektowego. Dzięki zrozumieniu tej struktury, programista może efektywnie zarządzać danymi i logiką aplikacji, stosując dobre praktyki takie jak enkapsulacja i modularność kodu.