Pytanie 1
Kolumna, która pełni funkcję klucza głównego w tabeli, powinna
A. być innego rodzaju niż inne kolumny
B. zawierać unikalne wartości
C. zawierać wartości liczbowe
D. posiadać ciągłą numerację
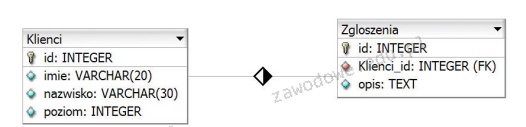
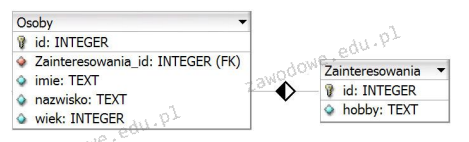
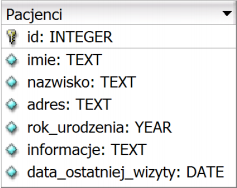
Klucz główny w tabeli bazy danych to naprawdę ważny element. To taki unikalny identyfikator, który pozwala na jednoznaczne rozróżnianie rekordów. Dzięki temu unikamy dublowania danych, co jest istotne, żeby wszystko było jasne i klarowne, bo jak byśmy mieli dwa takie same rekordy, to mogłoby być sporo zamieszania. Na przykład w tabeli 'Klienci' klucz główny to np. numery PESEL czy jakieś unikalne identyfikatory klientów. W praktyce stosuje się też różne standardy, jak SQL, które pomagają ustawić te klucze jako ograniczenia. To sprawia, że nasze dane są bezpieczniejsze i bardziej poprawne. No i tak z doświadczenia, najlepiej jest, jak klucz główny jest prosty, może jako liczba całkowita, bo wtedy wszystko działa szybciej. Podsumowując, unikalność klucza głównego to podstawa, żeby mieć pewność, że nasze dane są spójne i wiarygodne. To kluczowe w każdym systemie bazodanowym.