Pytanie 1
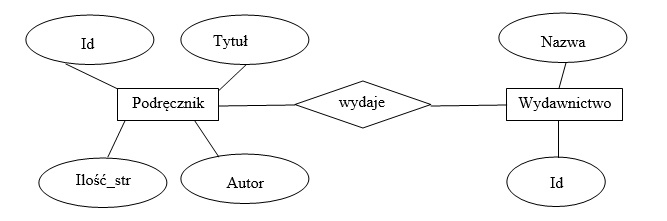
W tabeli artykuły wykonano następujące instrukcje dotyczące uprawnień użytkownika jan: ```GRANT ALL PRIVILEGES ON artykuly TO jan``` ```REVOKE SELECT, UPDATE ON artykuly FROM jan``` Po zrealizowaniu tych instrukcji pracownik jan będzie uprawniony do
A. tworzenia tabeli i wypełniania jej danymi
B. wyświetlania zawartości tabeli
C. tworzenia tabeli oraz edytowania danych w niej
D. edycji danych oraz przeglądania tabeli
Jan, po wydaniu polecenia GRANT ALL PRIVILEGES ON artykuly TO jan, miał pełne uprawnienia do wszystkich operacji na tabeli artykuly. Jednakże, po wykonaniu polecenia REVOKE SELECT, UPDATE ON artykuly FROM jan, jego uprawnienia do przeglądania danych (SELECT) oraz aktualizacji danych (UPDATE) zostały odebrane. Oznacza to, że Jan zachowuje możliwość tworzenia nowych tabel oraz wypełniania ich danymi (INSERT), ponieważ nie został ograniczony w tym zakresie. Możliwości tworzenia tabeli i wypełniania jej danymi są częścią przyznanych uprawnień. W standardzie SQL, komendy GRANT i REVOKE służą odpowiednio do przyznawania i odbierania uprawnień użytkownikom. W praktycznym zastosowaniu, takie operacje są kluczowe dla zarządzania bezpieczeństwem i dostępem do danych w bazach danych, co zapobiega nieautoryzowanym zmianom i zabezpiecza integralność danych.