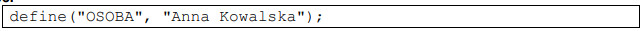Pytanie 1
W relacyjnych systemach baz danych, gdy dwie tabele są powiązane przez ich klucze główne, mamy do czynienia z relacją
A. n..n
B. 1..n
C. 1..1
D. n..1
W relacyjnych bazach danych, relacja 1..1 oznacza, że każdemu rekordowi w pierwszej tabeli odpowiada dokładnie jeden rekord w drugiej tabeli, a odwrotnie. Gdy tabele są połączone kluczem głównym, zapewnia to unikalność powiązań między nimi. Przykładami takich relacji mogą być tabele 'Pracownicy' i 'Konta', gdzie każdy pracownik ma jedno konto, a każde konto należy do jednego pracownika. Relacja 1..1 jest typowa w sytuacjach, gdy jedna tabela zawiera szczegółowe informacje o obiektach reprezentowanych w drugiej tabeli. Z perspektywy projektowania baz danych, stosowanie relacji 1..1 pomaga w minimalizowaniu redundancji danych oraz zwiększa spójność informacji. Praktyczne podejście do projektowania bazy danych sugeruje, aby relacje 1..1 były wykorzystywane tam, gdzie konieczne jest zapewnienie jednoznacznego powiązania danych, co wspiera integralność danych zgodnie z normami ACID (Atomicity, Consistency, Isolation, Durability).