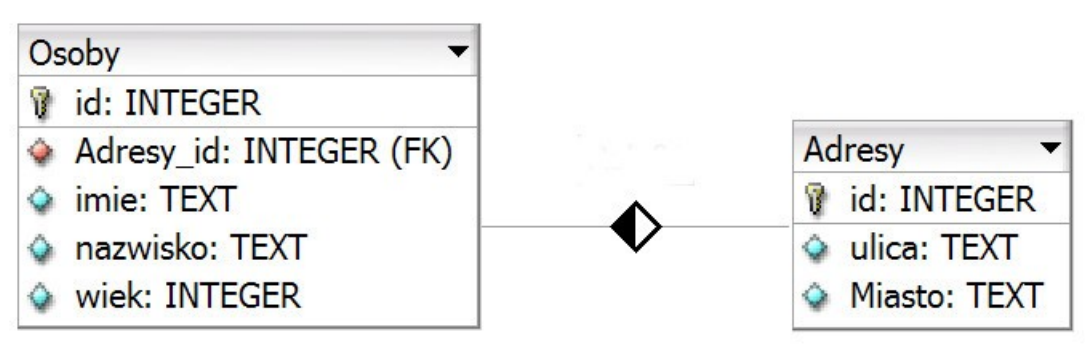
Pytanie 1
Na ilustracji przedstawiono schemat rozmieszczenia elementów na stronie WWW. W której z jej sekcji zazwyczaj znajduje się stopka strony?
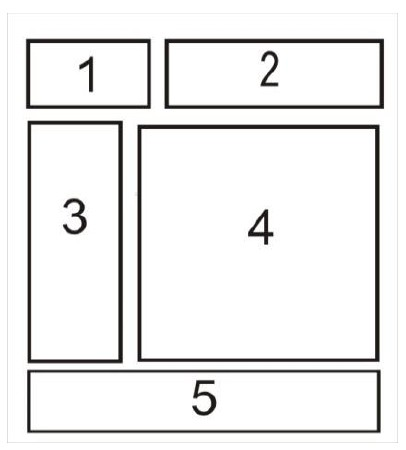
A. 2
B. 1
C. 4
D. 5
Odpowiedź 5 jest poprawna ponieważ w standardach projektowania stron internetowych stopka strony zazwyczaj znajduje się na dole każdej podstrony. Stopka to miejsce gdzie umieszczane są informacje takie jak prawa autorskie prywatność i linki do kontaktu. Dobrze zaprojektowana stopka może także zawierać skróty nawigacyjne które pomagają użytkownikowi szybko przemieszczać się po stronie. W praktyce projektanci stron WWW stosują podejście oparte na responsywnym designie co oznacza że stopka powinna być łatwo dostępna i czytelna na różnych urządzeniach. Wykorzystanie CSS Grid lub Flexbox pozwala na elastyczne zarządzanie układem strony co jest szczególnie przydatne przy projektowaniu stopki. Ponadto stopki są elementami które odpowiadają za spójność wizualną całej strony internetowej zapewniając użytkownikowi intuicyjne doświadczenie. Umieszczanie stopki w dolnej części strony jest zgodne z oczekiwaniami użytkowników co zwiększa użyteczność serwisu i pozytywnie wpływa na jego odbiór. Praktyczne zastosowanie tego podejścia można zauważyć na wielu profesjonalnych stronach gdzie stopka jest wyraźnie oddzielona i przejrzysta co ułatwia użytkownikowi odnalezienie potrzebnych informacji.