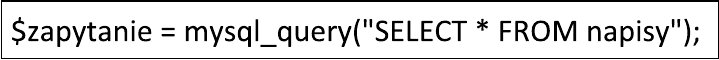Pytanie 1
W tabeli artykuly wykonano określone instrukcje dotyczące uprawnień użytkownika jan. Po ich realizacji użytkownik jan uzyska możliwość
| GRANT ALL PRIVILEGES ON artykuly TO jan REVOKE SELECT, UPDATE ON artykuly FROM jan |
A. edycji danych i przeglądania zawartości tabeli
B. sprawdzania zawartości tabeli
C. tworzenia tabeli i wypełniania jej informacjami
D. tworzenia tabeli oraz edytowania jej zawartości
Analizując pytanie i dostępną sekwencję poleceń SQL jasno wynika że użytkownik jan po wykonaniu tych poleceń nie zachowa uprawnień do przeglądania ani aktualizowania danych w tabeli artykuly. Pierwsze polecenie GRANT ALL PRIVILEGES przyznaje pełne uprawnienia co obejmuje tworzenie modyfikowanie usuwanie danych oraz ich przeglądanie. Jednakże drugie polecenie REVOKE SELECT UPDATE wycofuje konkretne prawa do przeglądania (SELECT) oraz aktualizowania (UPDATE) danych co oznacza że jan nie będzie mógł ani przeglądać ani modyfikować istniejących danych. To wyklucza odpowiedzi dotyczące aktualizowania danych i przeglądania tabeli jako poprawne. Często błędem jest założenie że cofnięcie tylko dwóch uprawnień nie wpłynie na możliwość podstawowych operacji takich jak przeglądanie. W rzeczywistości koordynacja uprawnień w bazach danych wymaga dokładnej analizy wszystkich przyznanych i cofniętych praw. Takie zarządzanie dostępem jest kluczowe dla zapewnienia bezpieczeństwa i integralności danych szczególnie w środowiskach produkcyjnych gdzie błędna konfiguracja może prowadzić do niepożądanych modyfikacji lub utraty danych.