Pytanie 1
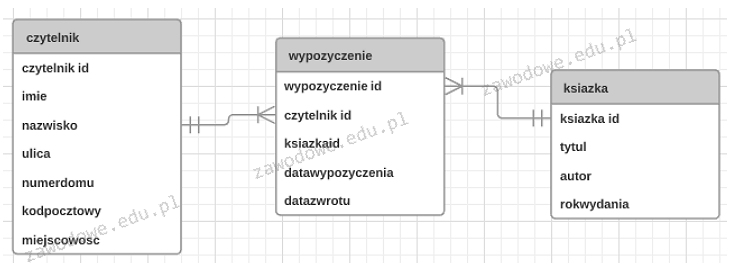
W językach programowania o układzie strukturalnym, aby przechować dane o 50 uczniach (ich imionach, nazwiskach oraz średniej ocen), konieczne jest zastosowanie
A. tablicy z 50 elementami o składowych typu łańcuchowego
B. struktury z 50 elementami o składowych typu tablicowego
C. tablicy z 50 elementami o składowych strukturalnych
D. klasy z 50 elementami typu tablicowego
Wybór tablicy 50 elementów o składowych strukturalnych jest prawidłowy ze względu na potrzebę przechowywania złożonych danych o uczniach. W tym przypadku, każdy element tablicy powinien reprezentować jednego ucznia i zawierać jego imię, nazwisko oraz średnią ocen. Struktura danych, taka jak struktura, pozwala na grupowanie różnych typów danych w jeden obiekt, co jest zgodne z dobrymi praktykami programowania w językach strukturalnych. Przykładowo, w języku C można zadeklarować strukturę dla ucznia w następujący sposób: `struct Uczen { char imie[50]; char nazwisko[50]; float srednia; };`. Następnie można utworzyć tablicę 50 elementów tej struktury: `struct Uczen uczniowie[50];`. Stosowanie struktur w tym kontekście ułatwia zarządzanie danymi i zwiększa czytelność kodu, co jest szczególnie ważne w przypadku projektów wymagających łatwego dostępu do różnych atrybutów obiektów. Używanie dobrze zdefiniowanych struktur danych jest zgodne z zasadami programowania obiektowego, nawet w językach proceduralnych, i przyczynia się do lepszej organizacji kodu oraz jego skalowalności.