Pytanie 1
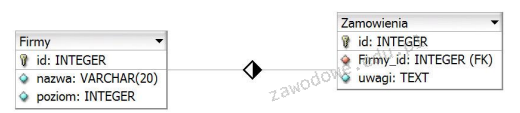
Zachowanie integralności encji w bazie danych będzie miało miejsce, jeżeli między innymi
A. każdej kolumnie przypisany zostanie typ danych
B. klucz główny zawsze będzie liczbą całkowitą
C. dla każdej tabeli zostanie ustanowiony klucz główny
D. każdy klucz główny będzie miał odpowiadający mu klucz obcy w innej tabeli
Wszystkie zaproponowane odpowiedzi mogą wydawać się związane z tematyką integralności encji, jednak nie każda z nich rzeczywiście przyczynia się do jej zachowania w kontekście baz danych. Użycie klucza głównego jako liczby całkowitej nie jest kryterium zapewniającym integralność; klucz główny może być również tekstowy lub złożony, o ile spełnia warunki unikalności i braku wartości NULL. Przypisanie typu danych dla każdej kolumny jest ważne dla sprawności operacji na danych, ale samo w sobie nie zapewnia integralności encji, ponieważ nie kontroluje unikalności rekordów. Kolejnym błędnym podejściem jest twierdzenie, że każdy klucz główny musi mieć odpowiadający klucz obcy w innej tabeli. Klucz obcy jest używany do ustanowienia relacji między tabelami, ale nie jest wymagany do zapewnienia integralności encji w pojedynczej tabeli. Klucz główny w jednej tabeli działa niezależnie od kluczy obcych w innych tabelach; jego główną rolą jest zapewnienie, że każdy rekord w tabeli jest unikalny. W praktyce, brak zrozumienia tych koncepcji może prowadzić do projektowania baz danych, które są nieefektywne i trudne do zarządzania, co w dłuższej perspektywie wpływa na jakość danych i ich dostępność.