Pytanie 1
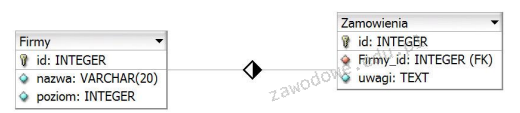
Pole autor w tabeli ksiazka jest:
CREATE TABLE ksiazka (
id INT UNSIGNED NOT NULL AUTO_INCREMENT PRIMARY KEY,
tytul VARCHAR(200),
autor SMALLINT UNSIGNED NOT NULL,
CONSTRAINT `dane` FOREIGN KEY (autor) REFERENCES autorzy(id)
);
A. kluczem obcym związanym z tabelą autorzy
B. kluczem podstawowym tabeli ksiazka
C. polem wykorzystanym w relacji z tabelą dane
D. polem typu tekstowego zawierającym informacje o autorze
Pole autor w tabeli ksiazka jest kluczem obcym, co oznacza, że wskazuje na inne pole w innej tabeli - w tym przypadku na pole id w tabeli autorzy. Klucze obce są podstawowym mechanizmem relacyjnych baz danych, który umożliwia tworzenie związków między różnymi tabelami. Dobre praktyki w projektowaniu baz danych sugerują używanie kluczy obcych do zapewnienia integralności referencyjnej, co oznacza, że każde odniesienie do innej tabeli musi wskazywać na istniejący rekord. Dzięki temu unika się problemów z danymi, takich jak tzw. „osierocone” rekordy, które odwołują się do nieistniejących danych. W praktyce, gdy dodajemy nową książkę do tabeli ksiazka, musimy mieć pewność, że istnieje odpowiedni autor w tabeli autorzy. Takie podejście podnosi jakość danych i pozwala na bardziej złożone zapytania SQL, które mogą łączyć informacje z różnych tabel w sposób spójny i logiki. Klucze obce są także kluczowe w kontekście operacji takich jak aktualizacja czy usuwanie danych, ponieważ mogą automatycznie zaktualizować lub usunąć powiązane rekordy, co zapewnia integralność bazy danych.