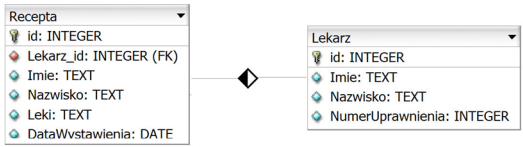
Pytanie 1
Aby zwiększyć wydajność operacji w bazie danych, należy skupić się na polach, które są często wyszukiwane lub sortowane
A. dodać klucz obcy
B. utworzyć indeks
C. dodać więzy integralności
D. stworzyć oddzielną tabelę przechowującą wyłącznie te pola
Dodawanie kluczy obcych nie jest bezpośrednią metodą na przyspieszenie operacji na bazie danych. Klucze obce są używane do zapewnienia integralności referencyjnej, co oznacza, że ich celem jest zapewnienie spójności danych w relacjach pomiędzy tabelami. Choć klucze obce mogą wpłynąć na wydajność w kontekście zapytań, nie przyspieszają one ani nie optymalizują wyszukiwania w obrębie pojedynczych tabel. Tworzenie osobnych tabel przechowujących tylko te pola również nie jest metodą optymalizacji efektywności wyszukiwania. Tego rodzaju podejście może prowadzić do komplikacji w zarządzaniu danymi oraz zmniejszenia wydajności przy łączeniu tabel w zapytaniach. Dodanie więzów integralności, które zapewniają, że dane w tabelach są poprawne i zgodne z określonymi zasadami, jest również istotne, ale nie wpływa bezpośrednio na szybkość operacji na bazie danych. Takie podejścia mogą prowadzić do błędnych przekonań, że poprawa wydajności bazy danych można osiągnąć poprzez wprowadzenie dodatkowych ograniczeń lub zmian w strukturze danych, co w rzeczywistości może generować dodatkowe koszty obliczeniowe przy wykonywaniu podstawowych operacji. Kluczowe jest stosowanie odpowiednich technik indeksacji, które są powszechnie uznawane za najlepszą praktykę w kontekście optymalizacji zasobów bazy danych.