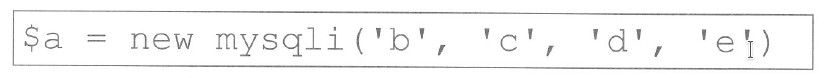Pytanie 1
Jaką funkcję w języku PHP należy wykorzystać, aby nawiązać połączenie z bazą danych o nazwie zwierzaki?
A. $polacz = db_connect('localhost', 'root','','zwierzaki');
B. $polacz = mysqli_connect('localhost', 'root','','zwierzaki');
C. $polacz = server_connect('localhost', 'root','','zwierzaki');
D. $polacz = sql_connect('localhost', 'root','','zwierzaki');
Odpowiedź $polacz = mysqli_connect('localhost', 'root','','zwierzaki'); jest poprawna, ponieważ funkcja mysqli_connect jest standardowym sposobem nawiązywania połączenia z bazą danych MySQL w języku PHP. Funkcja ta jest częścią rozszerzenia MySQLi, które oferuje bardziej zaawansowane możliwości w porównaniu do oryginalnego rozszerzenia MySQL. Umożliwia obsługę złożonych zapytań i zabezpieczeń, a także wspiera techniki programowania obiektowego. Warto zauważyć, że przy wywołaniu tej funkcji przekazujemy cztery argumenty: adres serwera (w tym przypadku 'localhost'), nazwę użytkownika ('root'), hasło (które jest puste w tym przypadku), oraz nazwę bazy danych ('zwierzaki'). Praktyczne zastosowanie tej funkcji jest kluczowe w kontekście aplikacji webowych, gdzie interakcja z bazą danych jest niezbędna. Na przykład, po nawiązaniu połączenia możemy wykonywać zapytania SQL, pobierać dane, a także dodawać nowe rekordy. Warto również dodać, że przed użyciem tej funkcji, powinniśmy zawsze sprawdzić, czy rozszerzenie MySQLi jest zainstalowane i aktywne, co jest zgodne z dobrymi praktykami programistycznymi.