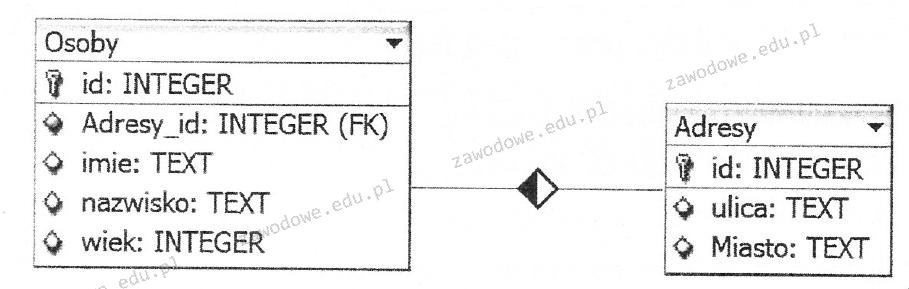
Pytanie 1
Jaką treść komunikatu należy umieścić w kodzie PHP zamiast znaków zapytania?
| $a = mysql_connect('localhost', 'adam', 'mojeHaslo'); if (!$a) echo "?????????????"; |
A. Błąd w trakcie przetwarzania zapytania SQL
B. Wybrana baza danych nie istnieje
C. Rekord został pomyślnie dodany do bazy
D. Błąd połączenia z serwerem SQL
Poprawna odpowiedź 'Błąd połączenia z serwerem SQL' jest właściwa, ponieważ funkcja mysql_connect() służy do nawiązywania połączenia z serwerem bazy danych MySQL. Jeśli połączenie nie powiedzie się, zwraca false. W takiej sytuacji należy poinformować użytkownika o nieudanym połączeniu. Jest to kluczowe w debugowaniu i zapewnianiu użytkownikowi zrozumiałych komunikatów błędów. W praktyce, połączenie z bazą danych jest podstawowym krokiem w wielu aplikacjach internetowych, a jego poprawna obsługa to standardowa praktyka branżowa. Współczesne podejście wymaga także użycia rozszerzenia mysqli lub PDO zamiast przestarzałej funkcji mysql_connect(). Jest to zalecane ze względu na lepsze wsparcie bezpieczeństwa i wydajności. Użycie funkcji mysqli_connect() pozwala na obsługę zarówno błędów połączenia, jak i zapytań SQL w sposób bardziej elastyczny i bezpieczny.