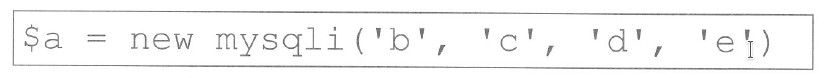Pytanie 1
Aby grupować obszary na poziomie bloków, które będą stylizowane za pomocą znacznika: należy wykorzystać
A. <param>
B. <p>
C. <div>
D. <span>
Element <div> to naprawdę ważna część HTML-a, bo pozwala na porządne grupowanie treści na stronie. Dzięki niemu możemy lepiej zorganizować dokument, co nie tylko wygląda estetycznie, ale też ma znaczenie dla semantyki. Używając <div>, łatwiej podpinamy style CSS i skrypty JavaScript, co bardzo pomaga w budowaniu responsywnych układów. Na przykład, gdy tworzymy stronę z nagłówkiem, głównym tekstem i stopką, to dobrze jest wrzucić te sekcje w odpowiednie <div>, bo potem łatwiej je stylizować i edytować. Trzeba pamiętać, że <div> nie ma swojej domyślnej semantyki, więc jego znaczenie zależy tylko od kontekstu, w jakim go użyjemy, co czyni go naprawdę wygodnym narzędziem w tworzeniu nowoczesnych stron.