Pytanie 1
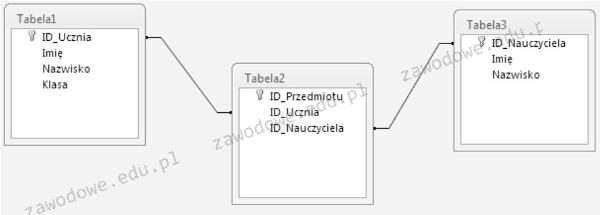
Głównym celem systemu CMS jest oddzielenie treści witryny informacyjnej od jej wyglądu. Jak osiągany jest ten efekt?
A. ze statycznych plików HTML oraz wyglądu ze zdefiniowanego szablonu
B. z bazy danych oraz wyglądu za pomocą atrybutów HTML
C. ze statycznych plików HTML oraz wyglądu za pomocą technologii FLASH
D. z bazy danych oraz wyglądu ze zdefiniowanego szablonu
Wykorzystanie statycznych plików HTML do generowania treści w kontekście systemów CMS jest koncepcją nieefektywną oraz niezgodną z współczesnymi standardami zarządzania treścią. Statyczne pliki HTML są trudne do aktualizacji, co oznacza, że każda zmiana wymaga edycji każdego pliku osobno. W praktyce prowadzi to do zwiększenia ryzyka błędów oraz obniża efektywność pracy, szczególnie w większych projektach. Z drugiej strony, wykorzystanie atrybutów HTML do definiowania wyglądu nie oddziela treści od prezentacji, co jest kluczowym założeniem CMS. Takie podejście nie tylko zagraża porządku w organizacji treści, ale także może negatywnie wpływać na dostępność oraz responsywność strony. Ponadto, technologia FLASH, która była popularna w przeszłości, obecnie nie jest wspierana przez większość przeglądarek i nie jest zalecana w nowoczesnym projektowaniu stron internetowych. Właściwe podejście do zarządzania treścią wymaga stosowania nowoczesnych narzędzi, takich jak bazy danych w połączeniu z szablonami, co zapewnia elastyczność i wygodę użytkowania. W ten sposób można efektywnie zarządzać zawartością oraz zapewnić optymalną wydajność i estetykę serwisu.