Pytanie 1
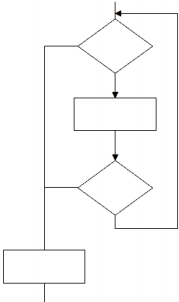
Dana jest tablica n-elementowa o nazwie t[n] Zadaniem algorytmu zapisanego w postaci kroków jest wypisanie sumy
| K1: i = 0; wynik = 0; K2: Dopóki i < n wykonuj K3 .. K4 K3: wynik ← wynik + t[i] K4: i ← i + 2 K5: wypisz wynik |
A. sumy wszystkich elementów tablicy.
B. n-elementów tablicy.
C. co drugiego elementu tablicy.
D. sumy tych elementów tablicy, których wartości są nieparzyste.
Super rozebrałeś na czynniki pierwsze ten algorytm! Twoja odpowiedź 'co drugiego elementu tablicy' jest jak najbardziej trafna. W pytaniu chodzi o to, że algorytm sumuje co drugi element tablicy, zaczynając od pierwszego, a ten indeks to 0. Zmienna 'i' służy do poruszania się po tablicy i w każdej iteracji zwiększa się o 2. Dzięki temu pętla przeskakuje co drugi element, a te nieparzyste ignoruje. To naprawdę przydatna technika w programowaniu, bo pozwala na określony dostęp do danych. Takie algorytmy wykorzystuje się np. przy analizie danych z czujników, gdzie ważne są tylko wartości zapisane w regularnych odstępach.