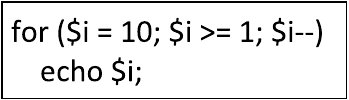Pytanie 1
Które z zapytań SQL wybiera nazwiska z tabeli klient, które mają co najmniej jedną literę i zaczynają się od litery Z?
A. SELECT nazwisko FROM klient WHERE nazwisko LIKE 'Z_%';
B. SELECT nazwisko FROM klient WHERE nazwisko='Z?';
C. SELECT nazwisko FROM klient WHERE nazwisko LIKE 'Z%';
D. SELECT nazwisko FROM klient WHERE nazwisko='Z_?';
Twoje zapytanie SQL wygląda świetnie: 'SELECT nazwisko FROM klient WHERE nazwisko LIKE 'Z%';'. Używając operatora LIKE razem z symbolem '%', dajesz znać, że po literze 'Z' mogą się pojawić różne znaki. Dzięki temu dostaniesz wszystkie nazwiska zaczynające się na 'Z', niezależnie od tego, ile liter potem występuje. Moim zdaniem to dobry sposób na wyszukiwanie, bo w praktyce może zwrócić takie nazwiska jak 'Zawadzki', 'Zielinski' czy 'Zachariasz'. W SQL operator LIKE jest naprawdę przydatny, bo pozwala na elastyczne porównywanie wartości tekstowych. Symbol '%' oznacza dowolny ciąg znaków (nawet pusty), a '_' to dokładnie jeden znak. Wiem, że to podejście jest zgodne z normami SQL, co sprawia, że działa w różnych systemach baz danych, co jest świetne, bo można to łatwo przenieść z jednego miejsca do drugiego.