Pytanie 1
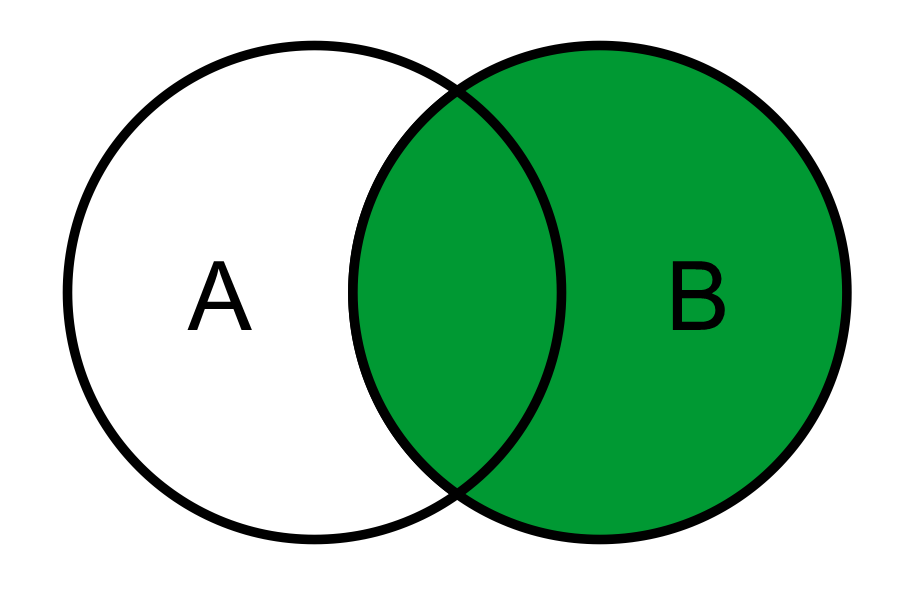
W języku SQL, aby wybrać wszystkie rekordy z tabeli B, w tym część wspólną z tabelą A, należy zastosować typ związku
A. A LEFT JOIN B
B. A INNER JOIN B
C. A FULL OUTER JOIN B
D. A RIGHT JOIN B
W tym pytaniu pułapka polega na tym, że łatwo pomylić pojęcie części wspólnej z całością jednego ze zbiorów. Diagram pokazuje całą tabelę B (włącznie z przecięciem z A), a nie tylko przecięcie. W SQL typ złączenia określa, z której tabeli bierzemy wszystkie rekordy, a z której tylko te pasujące. To, że widzimy też obszar wspólny, jest naturalnym efektem działania złączeń zewnętrznych, ale nie oznacza jeszcze, że chodzi o `INNER JOIN`. Jeśli ktoś wybiera `A LEFT JOIN B`, to zwykle wynika z myślenia „chcę część wspólną i coś jeszcze”, ale myli kierunek. `LEFT JOIN` gwarantuje wszystkie rekordy z **lewej** tabeli (A), a z prawej (B) tylko dopasowane. Diagram z pytania pokazuje dokładnie odwrotną sytuację: komplet danych z B, a z A tylko tam, gdzie istnieje relacja. `A LEFT JOIN B` odpowiadałoby sytuacji, gdzie podświetlony jest cały zbiór A i przecięcie, a nie B. Z kolei `A INNER JOIN B` zwróciłby wyłącznie część wspólną A∩B, czyli tylko te rekordy, które mają dopasowanie po obu stronach. Na diagramie byłby wtedy zaznaczony wyłącznie środek, a nie cały zielony obszar B. To typowy błąd: utożsamianie każdego JOIN z „częścią wspólną”. INNER JOIN jest dobry, gdy interesują nas tylko powiązane dane (np. zamówienia, które mają istniejącego klienta), ale w zadaniu wyraźnie mowa o „wszystkich rekordach z B”. `A FULL OUTER JOIN B` idzie w drugą stronę – zwraca wszystko z A **i** wszystko z B, niezależnie od tego, czy jest dopasowanie, czy nie. To byłby diagram z zaznaczonymi obiema kółkami, czyli suma zbiorów A∪B. W standardzie SQL taki typ złączenia jest opisany jako pełne złączenie zewnętrzne i stosuje się go rzadziej, np. do porównywania różnic między dwiema tabelami. Tutaj jest to za szeroki zakres danych w stosunku do pytania. Poprawne podejście wymaga więc skojarzenia, że skoro chcemy wszystkie rekordy z tabeli B, to w zapisie `A ... JOIN B` tabela B musi być po tej stronie, która jest „obowiązkowa”. Właśnie to zapewnia `RIGHT JOIN`: pełny zestaw wierszy z prawej tabeli, plus dopasowania z lewej tam, gdzie istnieją. Świadome operowanie tymi pojęciami bardzo ułatwia projektowanie zapytań raportowych i unikanie nieoczekiwanych braków lub duplikacji danych.