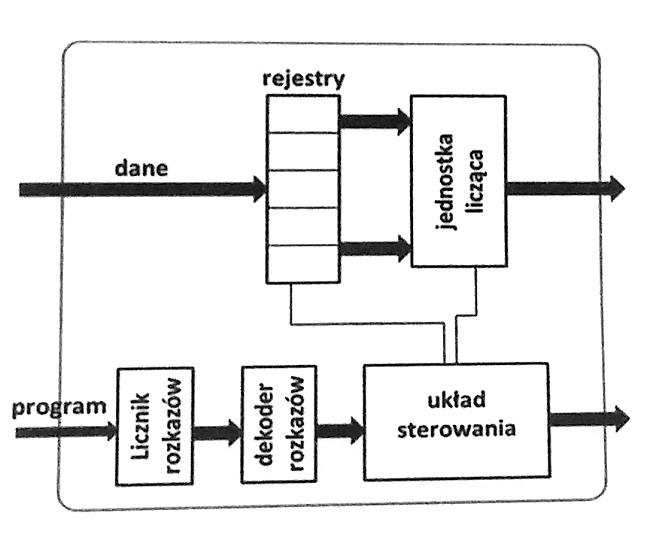
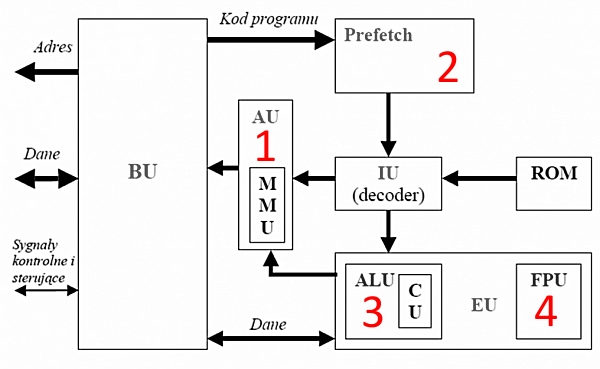
Pytanie 1
Aby zrealizować alternatywę logiczną z negacją, konieczne jest zastosowanie funktora
A. NOR
B. NAND
C. EX-OR
D. OR
Odpowiedź 'NOR' jest poprawna, ponieważ funkcja NOR jest podstawowym operatorem logicznym, który realizuje zarówno alternatywę, jak i negację. W logice, operator NOR jest negacją operatora OR, co oznacza, że zwraca wartość prawdziwą tylko wtedy, gdy oba argumenty są fałszywe. Jest to szczególnie ważne w projektowaniu układów cyfrowych, gdzie często dąży się do minimalizacji liczby używanych bramek logicznych. W praktyce, bramka NOR może być wykorzystana do budowy bardziej złożonych funkcji logicznych, w tym do implementacji pamięci w układach FPGA oraz w projektach związanych z automatyzacją. Zastosowanie bramek NOR jest również zgodne z zasadami projektowania cyfrowych systemów, które promują efektywność i oszczędność zasobów. Dodatkowo, bramka NOR jest wszechstronna, ponieważ można zbudować z niej wszystkie inne bramki logiczne, co czyni ją fundamentalnym elementem w teorii obwodów. Z tego względu, umiejętność korzystania z operatora NOR oraz zrozumienie jego działania jest kluczowe dla każdego inżyniera zajmującego się elektroniką.