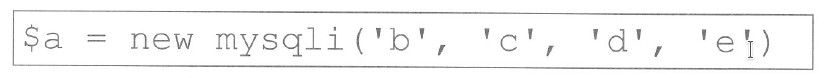Pytanie 1
Aby ustanowić połączenie z serwerem bazy danych w języku PHP, należy użyć funkcji
A. mysqli_get_connection_stats()
B. mysqli_connect()
C. mysqli_autocommit()
D. mysqli_fetch_row()
Funkcja mysqli_connect() to taka podstawa w PHP, która pomaga połączyć się z bazą danych MySQL. Musisz jej użyć z czterema argumentami: nazwą hosta, użytkownika, hasłem i nazwą bazy danych. Dzięki mysqli_connect() Twoja aplikacja będzie działać sprawniej i bezpieczniej, co jest mega ważne. Na przykład, żeby połączyć się z bazą, możesz użyć takiego kodu: $conn = mysqli_connect('localhost', 'username', 'password', 'database_name');. Jak już masz połączenie, to później możesz robić różne zapytania SQL i manipulować danymi. To też jest zgodne z zasadą separacji, bo oddziela logikę od zarządzania danymi. No i pamiętaj, że warto zadbać o obsługę błędów przy łączeniu, najlepiej sprawdzić to przy pomocy prostego warunku: if (!$conn) { die('Connection failed: ' . mysqli_connect_error()); } Moim zdaniem, to bardzo przydatne podejście.