Pytanie 1
W języku HTML zapisano formularz. Który z efektów działania kodu będzie wyświetlony przez przeglądarkę zakładając, że w pierwsze pole użytkownik przeglądarki wpisał wartość "Przykładowy text"?
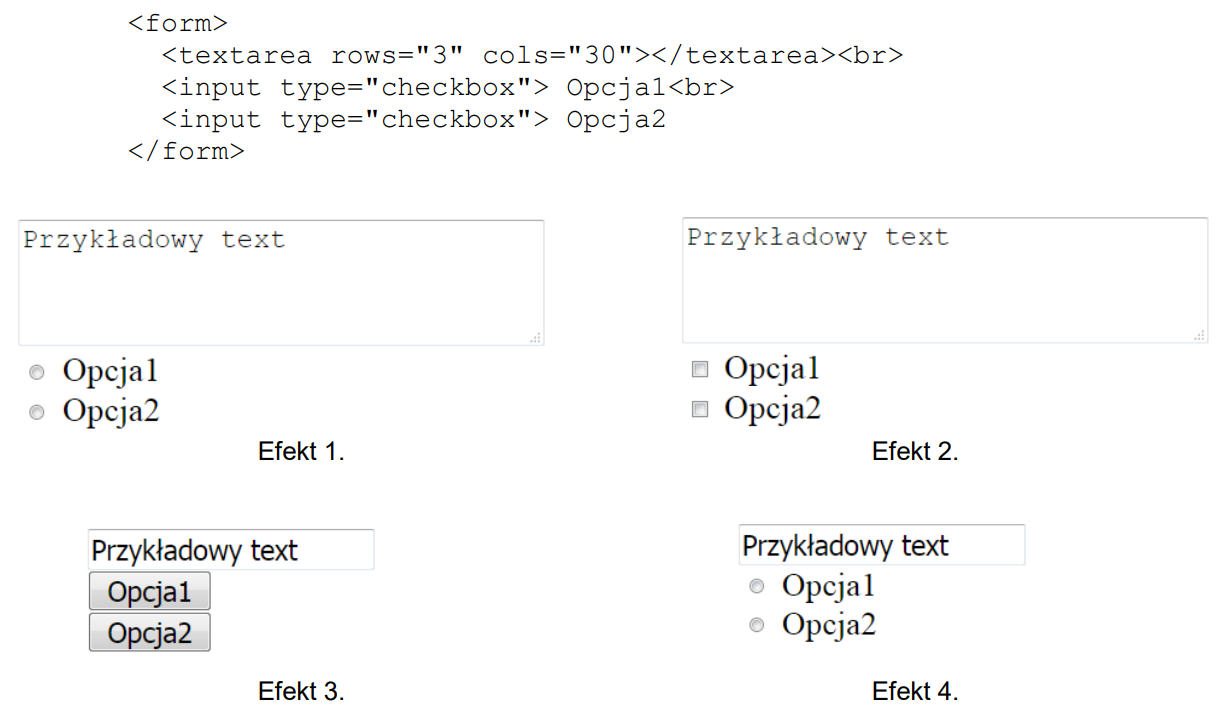
A. Efekt 1.
B. Efekt 2.
C. Efekt 4.
D. Efekt 3.
Odpowiedź, którą wybrałeś, nie jest poprawna, i wynika to z małego nieporozumienia dotyczącego formularzy HTML. Główna sprawa to to, że wszystko, co wpisujesz w polach formularza, jest pokazywane dopiero po jego przesłaniu. W tym przypadku, jeśli wprowadzisz 'Przykładowy text' w pole tekstowe, to będzie to widoczne, ale checkboxy będą niezaznaczone. Błędne odpowiedzi często pochodzą z mylenia działania checkboxów. Pamiętaj, że te dwa checkboxy są zawsze niezaznaczone, niezależnie od tego, co wprowadziłeś w pole tekstowe. I to, że wartość z pola tekstowego nie wpływa na checkboxy, można uznać za istotne zrozumienie działania formularzy HTML. Także warto zwrócić na to uwagę w przyszłości.