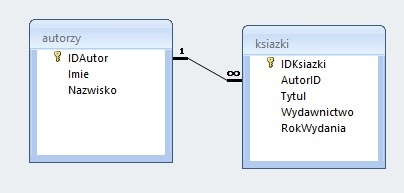
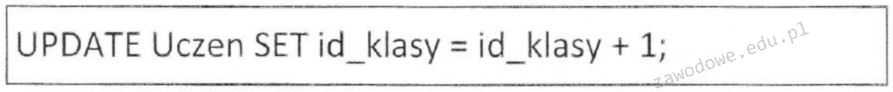Pytanie 1
Którego ograniczenia (constraint) użyć do zdefiniowania klucza OBCEGO?
A.
AUTO_INCREMENT(id)
B.
PRIMARY KEY(id)
C.
UNIQUE KEY(id)
D.
FOREIGN KEY(id)
Pozostałe ograniczenia robią co innego.
PRIMARY KEY ustanawia klucz GŁÓWNY, UNIQUE wymusza unikalność wartości, a AUTO_INCREMENT automatycznie numeruje. Klucz obcy definiuje FOREIGN KEY(id).