Pytanie 1
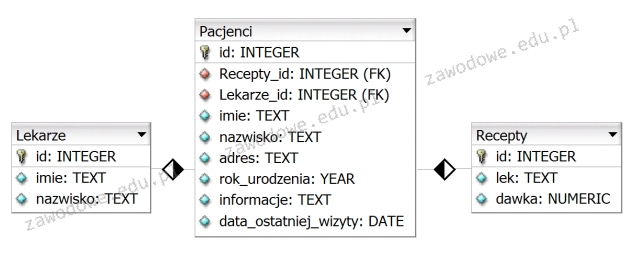
Tabela Pacjenci zawiera kolumny: imie, nazwisko, wiek, lekarz_id. Aby stworzyć raport, który będzie zawierał jedynie imiona oraz nazwiska pacjentów mających mniej niż 18 lat i zapisanych do lekarza o id równym 6, można wykorzystać kwerendę SQL
A. SELECT imie, nazwisko WHERE wiek<18 OR lekarz_id=6
B. SELECT imie, nazwisko FROM Pacjenci WHERE wiek<18 OR lekarz_id=6
C. SELECT imie, nazwisko FROM Pacjenci WHERE wiek<18 AND lekarz_id=6
D. SELECT imie, nazwisko WHERE wiek<18 AND lekarz_id=6
Aby uzyskać raport z tabeli Pacjenci, w którym znajdują się wyłącznie imiona i nazwiska pacjentów poniżej 18 roku życia zapisanych do lekarza o id równym 6, należy użyć następującej kwerendy SQL: SELECT imie, nazwisko FROM Pacjenci WHERE wiek<18 AND lekarz_id=6. Kluczowe w tej kwerendzie jest zastosowanie operatora AND, który pozwala na jednoczesne spełnienie obu warunków. W SQL, operator AND łączy dwa warunki, które muszą być prawdziwe, aby dany wiersz został uwzględniony w wynikach. Operator OR byłby nieodpowiedni, ponieważ mógłby zwrócić pacjentów, którzy są młodsi niż 18 lat, ale zapisani do innych lekarzy, co nie spełnia wymagań zadania. Ta kwerenda jest zgodna z ANSI SQL, który jest standardem dla zapytań do baz danych, a także dobrze ilustruje zasady filtracji danych w kontekście relacyjnych baz danych. Przykład takiej tabeli mógłby wyglądać następująco: imie: 'Jan', nazwisko: 'Kowalski', wiek: 17, lekarz_id: 6. W tym przypadku, zapytanie zwróciłoby imię i nazwisko Jana Kowalskiego, ponieważ spełnia on oba warunki.