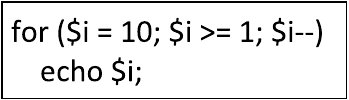Pytanie 1
Przy użyciu polecenia ALTER TABLE można
A. usuwać tabelę
B. zmieniać wartości zapisane w rekordach tabeli
C. tworzyć nową tabelę
D. zmieniać strukturę tabeli
Polecenie ALTER TABLE jest kluczowym narzędziem w zarządzaniu bazami danych, pozwalającym na modyfikację struktury istniejących tabel. Umożliwia m.in. dodawanie, usuwanie lub modyfikowanie kolumn, a także zmianę ich typów danych. Na przykład, aby dodać nową kolumnę do tabeli, można użyć polecenia: ALTER TABLE nazwa_tabeli ADD nowa_kolumna typ_danych. W praktyce, ALTER TABLE jest niezbędne w przypadku zmiany wymagań aplikacji, które mogą wymagać dostosowania struktury bazy danych. Zmiany strukturalne powinny być przeprowadzane zgodnie z zasadami normalizacji, co zapewnia optymalizację bazy danych oraz zapobiega redundancji danych. Kluczowe jest również testowanie wprowadzonych zmian w środowisku testowym przed ich wdrożeniem w produkcji, co jest zgodne z najlepszymi praktykami w inżynierii oprogramowania. Warto również pamiętać, że podczas modyfikacji struktury tabeli, odpowiednie zrozumienie relacji między tabelami jest istotne dla zachowania integralności danych.