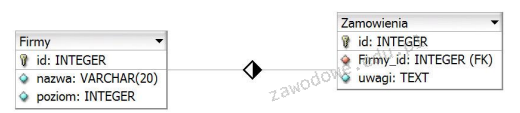
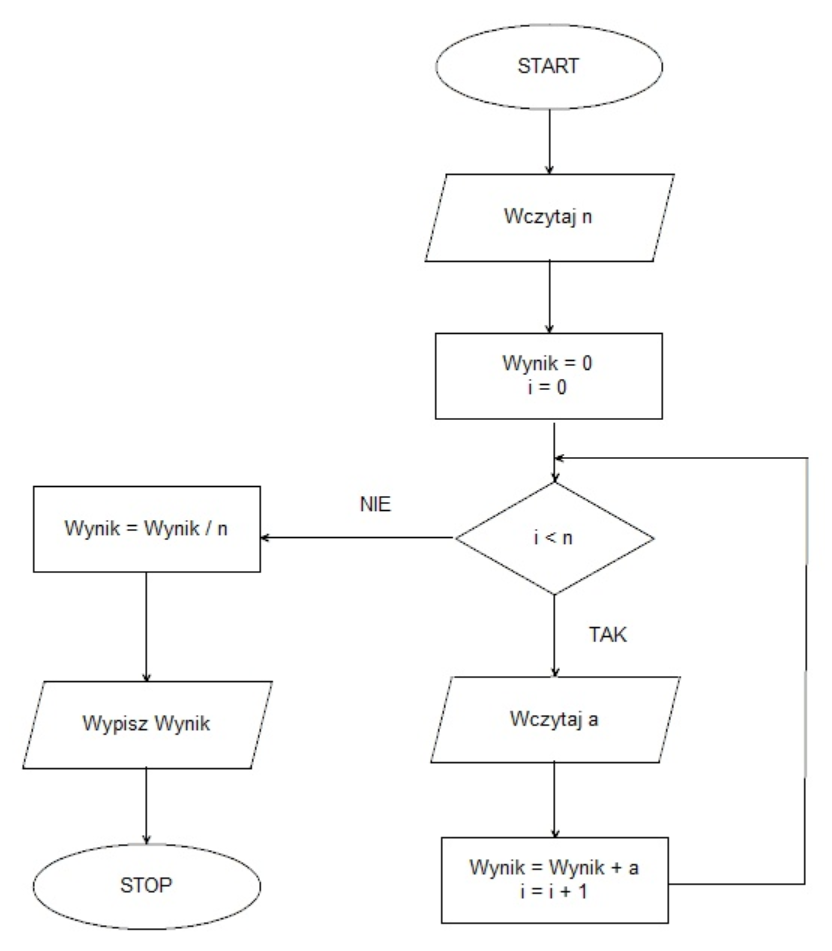
Pytanie 1
W systemie zarządzania bazami danych MySQL komenda CREATE USER pozwala na
A. pokazanie danych o istniejącym użytkowniku
B. zmianę hasła dla już istniejącego użytkownika
C. stworznie nowego użytkownika oraz przydzielenie mu uprawnień do bazy
D. utworzenie użytkownika
Odpowiedzi sugerujące utworzenie użytkownika i nadanie mu praw do bazy lub wyświetlenie informacji o istniejącym użytkowniku nie są poprawne, ponieważ CREATE USER służy jedynie do definicji konta użytkownika, a nie do przypisywania mu uprawnień. W rzeczywistości, aby przyznać dostęp do bazy danych, należy użyć osobnego polecenia GRANT, które zarządza uprawnieniami dla już istniejących użytkowników. Z tego powodu pomylenie tych dwóch poleceń może prowadzić do nieefektywnego zarządzania użytkownikami w systemie bazy danych. Innym błędnym podejściem jest przypisanie funkcji wyświetlania informacji o użytkownikach do CREATE USER. W MySQL do uzyskania takich informacji wykorzystuje się zapytania do systemowych tabel informacyjnych lub polecenie SHOW GRANTS, które pozwala na przeglądanie przyznanych uprawnień dla konkretnego użytkownika. Z kolei zmiana hasła istniejącego użytkownika z wykorzystaniem CREATE USER jest również pomyłką, gdyż do takiej operacji należy używać polecenia ALTER USER, co pozwala na aktualizację danych logowania bez konieczności usuwania i ponownego tworzenia konta. Błędy te wynikają często z niepełnego zrozumienia funkcji poszczególnych poleceń SQL, co może prowadzić do nieefektywnego zarządzania bazą danych oraz zwiększonego ryzyka bezpieczeństwa.