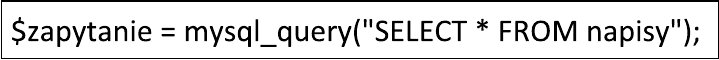Pytanie 1
Jaką rolę pełni funkcja PHP o nazwie mysql_select_db()?
A. określić tabelę, z której będą pobierane informacje
B. określić bazę, z której będą pobierane dane
C. pobrać dane z bazy danych na podstawie zapytania
D. nawiązać połączenie bazy danych z serwerem SQL
Funkcja mysql_select_db() służy do określenia, która baza danych będzie używana w kontekście bieżącego połączenia z serwerem MySQL. W momencie, gdy nawiązuje się połączenie z serwerem za pomocą funkcji mysql_connect(), należy jasno zdefiniować, w której bazie danych będą wykonywane zapytania. Właściwe ustawienie aktualnej bazy danych jest kluczowe, ponieważ wszelkie operacje związane z pobieraniem lub modyfikowaniem danych będą odnosiły się tylko do tej wskazanej bazy. Przykładowo, jeżeli mamy bazę danych 'sklep' i chcemy pobrać dane o produktach, najpierw musimy wywołać mysql_select_db('sklep'). Dobrą praktyką jest również sprawdzenie, czy operacja wyboru bazy danych zakończyła się sukcesem, co można zrobić, sprawdzając zwracany wynik. Należy pamiętać, że funkcja mysql_select_db() jest częścią starzejącego się interfejsu MySQL, a w nowoczesnych aplikacjach rekomendowane są bardziej aktualne rozszerzenia, takie jak MySQLi lub PDO, które oferują lepsze możliwości obsługi błędów oraz bezpieczeństwo.