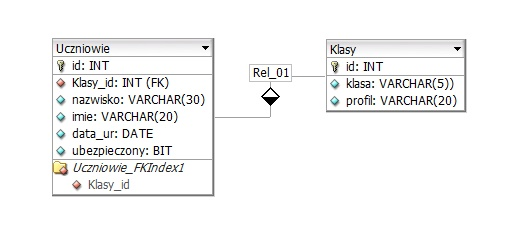
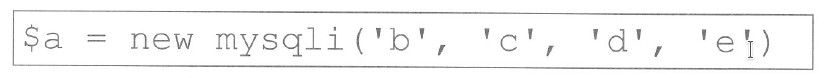Pytanie 1
W podanym fragmencie zapytania w języku SQL, komenda SELECT jest używana do zwrócenia SELECT COUNT(wartosc) FROM …
A. summy w kolumnie wartosc
B. średniej w kolumnie wartosc
C. ilości wierszy
D. średniej wartości z tabeli
No, trochę jest tu pomyłka. Ludzie często mylą to zapytanie SELECT COUNT(wartosc) z sumowaniem wartości, co nie jest do końca poprawne. Funkcja COUNT nie sumuje wartości, ona tylko liczy, ile jest niepustych wierszy. Więc jeżeli ktoś twierdzi, że to daje średnią, to wprowadza w błąd – średnią liczymy z pomocą funkcji AVG, a nie COUNT. W kolumnie 'wartosc' mogą być różne liczby, a suma wartości nie ma wiele wspólnego z tym, ile jest wierszy. Dobrze jest pamiętać, że średnia to coś innego niż liczba wierszy, co jest ważne do zrozumienia, jak działają zapytania w SQL. Jeśli ktoś myli te funkcje, to może się zgubić w analizie danych. Więc ogólnie mówiąc, warto wiedzieć, czym różnią się COUNT, AVG i inne funkcje agregujące, bo to kluczowe do ogarnięcia pracy z bazami danych.