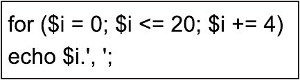Pytanie 1
Fragment skryptu w języku JavaScript umieszczony w ramce
| t = "Ala ma kota."; s = t.length; |
A. wyświetli długość tekstu z zmiennej t
B. przypisze zmiennej s zmienną t
C. przypisze zmiennej s długość tekstu z zmiennej t
D. przypisze zmiennej s część tekstu z zmiennej t, o długości określonej przez zmienną length
Błędne przypuszczenie że kod wyświetli długość napisu ze zmiennej t wynika z niezrozumienia różnicy między przypisaniem a wyświetleniem wartości. W podanym przykładzie zmienna s przechowuje długość napisu ale kod nie zawiera żadnej instrukcji wyświetlenia tej wartości. W JavaScript do wyświetlenia w konsoli wymagane jest użycie funkcji console.log co nie zostało tu zawarte. Następnie błędna odpowiedź dotycząca przypisania fragmentu napisu wskazuje na niezrozumienie zastosowania właściwości length która zwraca całkowitą długość łańcucha a nie jego część. Aby uzyskać fragment łańcucha należałoby użyć metody substring lub slice które tej funkcji tutaj nie ma. Ostatnia błędna odpowiedź sugerująca że zmienna s przechowuje cały napis z t wykazuje brak zrozumienia samego przypisania w kontekście obiektów stringowych w JavaScript. Gdyby celem było przypisanie całego łańcucha należałoby użyć samego t bez length. Zrozumienie różnic w działaniach właściwości i metod w JavaScript jest kluczowe w skutecznym programowaniu i unikania błędów logicznych które mogą prowadzić do nieoczekiwanych rezultatów w działaniu aplikacji.