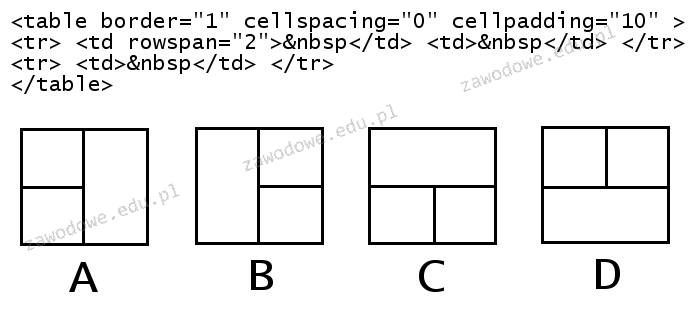
Pytanie 1
Jakiej kwerendy w bazie MariaDB należy użyć, aby wybrać artykuły, których ceny mieszczą się w przedziale domkniętym <10, 20>?
A. SELECT * FROM Artykuly WHERE Cena > 10 AND Cena < 20
B. SELECT * FROM Artykuly WHERE Cena BETWEEN 10 AND 20
C. SELECT * FROM Artykuly WHERE Cena IN (10, 20)
D. SELECT * FROM Artykuly WHERE Cena LIKE 1%, 2%
Odpowiedź 'SELECT * FROM Artykuly WHERE Cena BETWEEN 10 AND 20;' jest prawidłowa, ponieważ wykorzystuje operator BETWEEN, który jest idealny do określenia wartości zawartych w obustronnie domkniętym przedziale. W tym przypadku zapytanie zwróci wszystkie artykuły, których cena jest równa 10 lub 20 oraz wszystkie wartości znajdujące się pomiędzy tymi dwoma wartościami. Operator BETWEEN jest standardowym sposobem na łatwe zapisywanie takich warunków w SQL, co czyni kod bardziej czytelnym i zrozumiałym. Przykład zastosowania to sytuacja, gdy chcemy znaleźć produkty w określonym przedziale cenowym na stronie e-commerce. Tego typu kwerendy są bardzo powszechne w analizie danych i zarządzaniu bazami danych, a ich znajomość jest kluczowa dla efektywnego wykonywania zadań związanych z eksploracją danych. Zastosowanie BETWEEN w praktyce pozwala na automatyzację procesów wyszukiwania i filtrowania danych, co jest zgodne z najlepszymi praktykami w zakresie optymalizacji zapytań w bazach danych.