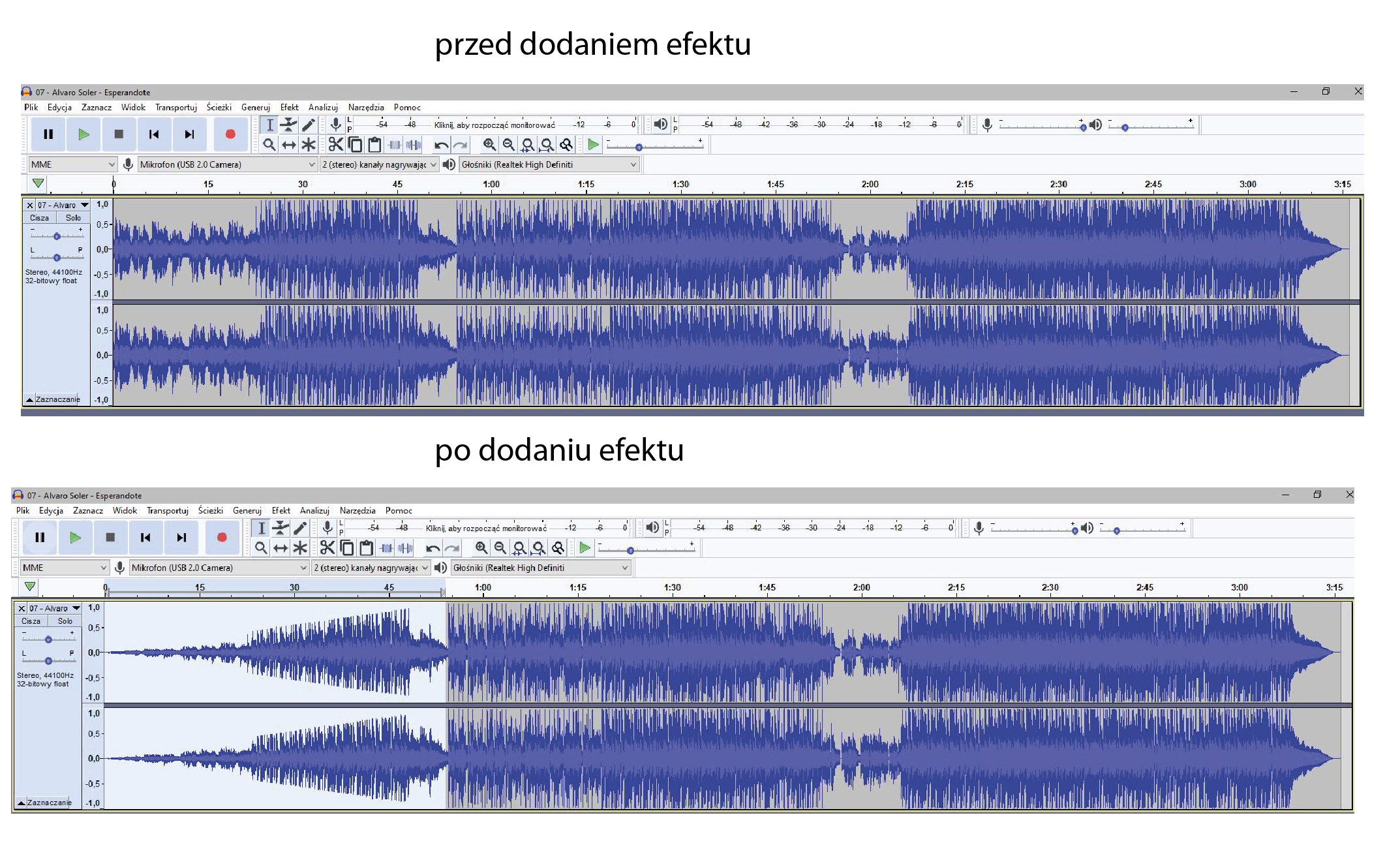
Prawidłowo – na ścieżkę został nałożony efekt zgłaśniania (ang. fade in). Na górnym wykresie widzisz oryginalny przebieg fali: poziom głośności jest praktycznie stały od samego początku utworu, amplituda sygnału jest od razu dość duża. Na dolnym wykresie początek nagrania ma bardzo małą amplitudę, która stopniowo rośnie, aż osiąga pełny poziom głośności. Właśnie tak wygląda klasyczne zgłaśnianie: sygnał startuje od ciszy lub półciszy i płynnie przechodzi do docelowej głośności. W programach typu Audacity realizuje się to zwykle komendą „Zgłaśnianie” lub „Fade In”, która modyfikuje obwiednię głośności, a nie samą strukturę częstotliwościową dźwięku. W praktyce takie rozwiązanie stosuje się na początku piosenek, w podkładach do prezentacji, podcastach czy filmach, żeby uniknąć nagłego, nieprzyjemnego „uderzenia” dźwięku. Jest to jedna z podstawowych dobrych praktyk montażu audio – szczególnie w radiu i w postprodukcji wideo, gdzie dba się o komfort słuchacza i estetykę przejść. Z mojego doświadczenia, delikatne zgłaśnianie na 1–3 sekundy na starcie utworu sprawia, że cały materiał brzmi od razu bardziej profesjonalnie i „radiowo”. Warto też pamiętać, że efekt zgłaśniania jest często łączony z wyciszaniem (fade out) na końcu ścieżki, co razem daje bardzo płynne wejście i wyjście utworu, zgodnie z typowymi standardami pracy w studiu dźwiękowym.
Na ilustracji pokazano klasyczny przykład zastosowania efektu zgłaśniania, czyli płynnego narastania głośności w czasie. Dobrze widać, że amplituda sygnału na początku ścieżki jest bliska zera i stopniowo rośnie, aż osiąga pełny poziom. To jest modyfikacja obwiedni głośności, a nie struktury utworu czy jego tempa. Częsty błąd polega na myleniu różnych typów operacji audio tylko na podstawie ogólnego wrażenia. Efekt karaoke polega zazwyczaj na próbie usunięcia lub mocnego osłabienia wokalu z gotowego miksu, często przez odejmowanie kanałów środkowych lub manipulację fazą. Taka operacja nie zmienia kształtu fali w czasie w sposób stopniowy od zera do maksimum; bardziej wpływa na zawartość częstotliwościową i relacje między kanałami stereo. Na wykresie nic nie wskazuje na usunięcie wokalu, widać jedynie zmianę poziomu głośności na początku. Z kolei zmiana tempa dotyczy długości trwania materiału – ścieżka byłaby wyraźnie skrócona albo wydłużona, ewentualnie zmieniłaby się gęstość próbek w czasie. W prezentowanym przykładzie czas trwania utworu pozostaje praktycznie taki sam, a charakter gęstości sygnału po osiągnięciu pełnej głośności jest bardzo podobny do oryginału, co oznacza, że tempo nie zostało naruszone. Przenikanie ścieżek to natomiast sytuacja, gdy dwie różne ścieżki nakładają się na siebie: jedna jest wyciszana, druga w tym samym czasie zgłaśniana. Na ekranie widzielibyśmy wtedy dwie ścieżki i ich przeciwne zmiany głośności, stosowane typowo przy przejściach między utworami w montażu wideo lub miksie DJ-skim. Tutaj obserwujemy pracę tylko na jednej ścieżce, bez drugiego materiału, więc nie ma mowy o przenikaniu. Moim zdaniem dobrze jest zawsze patrzeć na kształt amplitudy w czasie i zadać sobie pytanie: czy zmienia się głośność, zawartość częstotliwości, czy długość nagrania – to bardzo pomaga uniknąć takich pomyłek w praktycznej pracy z dźwiękiem.